
|
Персональные инструменты
Просмотры |
|
Персональные инструменты |
|||
|
|
Разработка видеохостинга на Erlang (Максим Лапшин на ADD-2010)Материал из CustisWikiКороткая ссылка: 104-ErlyVideo-Erlang-add-2010 Содержание
Аннотация
Видео
Подкаст
Презентация                                                Стенограмма
Что такое стриминг?Добрый день, меня зовут Максим Лапшин, я автор видеостримингового сервера ErlyVideo, написанного на Erlang, и сегодня я бы хотел вам рассказать, что это за продукт, зачем он был сделан, … что это такое, зачем я все это сделал. Итак, что такое стриминг вообще. Ютуб — это не стримингЧто такое YouTube? Там храниться огромное количество разного видео, но это не стриминговый проект, там нет стриминга. Там просто десятисекундные ролики, которые выдаются вам nginx-oм, ну или другим вебсервером. Каждый броузер заходит, получает какой-то ролик и его проигрывает. Но это не имеет никакого отношения к потоковому видео. Где же тогда все это используется, к чему это все?
Пользовательское ТВПользователь загружает видеофайлы
Давайте рассмотрим задачу пользовательского телевидения, которая у меня недавно стояла. Значит, идея в чем — пользователь загружает свои файлы, почти как в ютуб, потом формирует из них плейлист, который он хочет, чтобы показывался как телепрограмма на обычном телевидении. После чего, другие пользователи в какое-то время приходят, не обязательно в нужное время. Они приходят когда угодно, видят его интересный плейлист, им нравится его программа, они хотят посмотреть, что же он наснимал. И потом, когда все пользователи расходятся, им стало неинтересно, необходимо все эти ресурсы, которые были закачаны, освободить.
Вроде как обкатанная технология, у того же ютуба работает, но нет, не работает. Что делает стример?Что делает стример?
Проблема вся в том, что необходимо имеющиеся файлы отдавать в видеопоток. Потому что необходимо монотонно всем пользователям показывать одно и тоже. Для этой задачи как раз нужен стример, то есть сервер потокового видео, который сделает вот что.
Значит, если вы зашли, вы за полчаса получаете реального времени по часам вы получите полчаса реального времени, которые из файла. Если вы просто скачиваете файл, вы бы могли гораздо быстрее скачать. Отступление про кодекиМаленькое отступление, чтобы все понимали, что такое кодеки и контейнеры, чтобы не было путаницы. Кодек, это то, во что у вас ужато то… , это формат представления сырых данных, которые захватываются с матрицы видеокамеры, или там с микрофона. Контейнер — это то, во что упаковываются уже закодированные данные. Например, если вы встретили h264 или AAC, то это видео и аудиокодеки, соответсвенно. А MP4 … — нет такого кодека, это контейнер, в который можно убрать абсолютно любое видео и абсолютно любой звук.
Этапы User TVЭтапы User TV
Итак, чем же занимается сервер, показывая пользовательское телевидение? Он скачивает плейлисты, распаковывает файлы, перепаковывает их, зачищает все, и очень важная вещь, про которую я отдельно не упомянул, это то, что в этой задаче очень важно обновлять код, не отключая клиентов, потому что бывает до тысячи, … многих тысяч клиентов, которые пришли посмотреть интересное видео. Если мы захотим в этот момент выкатить апдейт под них, то эти тыщи клиентов опять к нам придут, реконнектится. Помимо того, что это банально просто неудобство для пользователей, это еще и очень-очень-очень дорого, потому, что наш трафик забьется полностью. Традиционные способы решенияНа чем это обычно люди делают, такие решения? Традиционные способы решения, это традиционные инструменты — Java, С++, на них есть продукты, которые занимаются потоковым видео. Это например, Red5, бесплатный, платная Wowza, написанная на Java, либо это rtmpd, написанный на C++.
Парсинг mp3 на JavaВ чем проблема…? Ну вот пример я привел, это маленький кусочек кода, как парсится RTMP на Java, это маленький кусочек кода, одна сотая файла. Вот так выглят любой сервер на Java, можно присматриваться — это малая, малая, часть файла. Вникнуть в это очень сложно. if (id3v1 instanceof ID3V1_1Tag) { try { // Add the track property graph.add(mp3Resource, processor.resolveIdentifier(IdentifierProcessor.TRCK), factory.createLiteral("" + ((ID3V1_1Tag) id3v1).getAlbumTrack())); } catch (GraphException graphException) { throw new ParserException( "Unable to add track number to id3v1 resource.", graphException); } catch (GraphElementFactoryException graphElementFactoryException) { throw new ParserException( .... ещѐ 600 строк кода graphElementFactoryException); } } Парсинг mp3 на ErlangЭто все, что нужно написать на Erlange, чтобы декодировать MP3. Все. Пять строчек. Оно уже все распаковано и можно отправлять пользователям.
decode(<<2#11111111111:11, VsnBits:2, LayerBits:2, _:1, BitRate:4, _/binary>> = Packet) ->
Layer = layer(LayerBits),
Version = version(VsnBits),
<<Frame:(framelength(bitrate({Version,Layer}, BitRate))/binary, Rest/binary>> = Packet,
{ok, Frame, Rest}.
Но все становится…, весь этот синтаксический сахар, все это становится, совершенно неважным, когда к нам приходят тысячи клиентов. И у нас начинается проблемы совершенно нового характера, без связи с тем, удобно или неудобно там писать код. В чем же проблема? Ну это все как всегда: управление памятью, так чтобы не текло, и не ловились сегфолты, это контроль за ресурсами клиентов, которые к нам пришли, которых надо запомнить, и кому чего и когда нужно, чтобы эффективно осовбодить память. В случае C++, у нас есть другая проблема, Java позволяет как-то защитить код за счет отсутствия прямой работы с памятью. В C++ ошибка в одном месте, особенно если у вас многотредное приложение, она вам может разрушить все приложение, и вы никогда не отладите этот баг. Вы можете быть гарантированно уверены, что в любой программе на C++, особенно многотредной, есть баг, который вы еще просто не нашли, даже не рассчитывате, что он там есть. И другая проблема, что когда у вас начинаются тысячи клиентов, вам необходимо сложно организовывать ввод-вывод. Вам недостаточно просто использовать треды, и просто писать в сокет, вам необходимо использовать сложные библиотеки либо eventы, которые использоуют разные сложные механизмы. Проблемы классических решений при тысячах клиентов
Что же получается? Сервер Red5 валится под сотней пользователей. Эх, тут к сожалению, не красная получилось (см. картинку с унылым запорожцем…)  Уже на ста пользователях сервер валится и не обслуживает клиентов. Почему? Да потому, что он написан плохо, при его разработке люди не учитывали, вопрос ввода-вывода, и вот, он просто перестает обслуживать.
 В случае с Wowza, у нас возникают другие проблемы, которые возникали у моих клиентов — у них Вовза течет, несмотря на то, что в яве есть сборщик мусора, где-то какая-то ссылка осталась, ресурсы не освобождаются, сервер разбухает, и вот так вот страшно выглядит. Как это получается? Ну например, у нас стриминговый сервер обслуживает еще какой-то канал доставки сообщений. Пользователь логинится, обьект, который для него был создан, регистрируется по какому-то каналу в списке, ссылка на него запоминается, тест на обьект будет держаться, пользователь отключается, но мы забыли, мы забыли убрать ссылку на него. Все. Его данные остались навсегда, мы не можем получить информацию, что надо отключить. И все, до рестарта сервера.
epoll/kqueue сложны для долгих соединений из-за управления памятью. Что же касается ввода-вывода, то механизмы epoll/kqueue, для которых есть библиотеки libevent, это единственный способ обслуживать тысячи сокетов, они очень, очень сложны, для … когда у вас начинается сложная бизнес-логика…, потому что эффективное управление памятью в eventной модели, по-моему, безумно сложно.
 Вот, получается такая конструкция с С++ным сервером. Вы гарантированно начинаете ваш рабочий день с того, что вы выгребаете core-ки, сохранившиеся за ночь на файловой системе и хорошо, если вам хватило жесткого диска.
Корни проблемВ чем-то корни этих проблем которые кроются, общие для традиционных решений. Во-первых, это общая память.  Вот, к сожалению, картинка опять не видна. Общая память, которая разделяется между всеми объектами, которые есть в системе. Кто угодно может пойти куда угодно, взять ссылку на что угодно, и в итоге, получается вот такая конструкция, когда все объекты перекрестно друг на друга ссылаются, и нам гораздо сложнее в этой ситуации контролировать память, кто и что захватил, и кому что нужно. 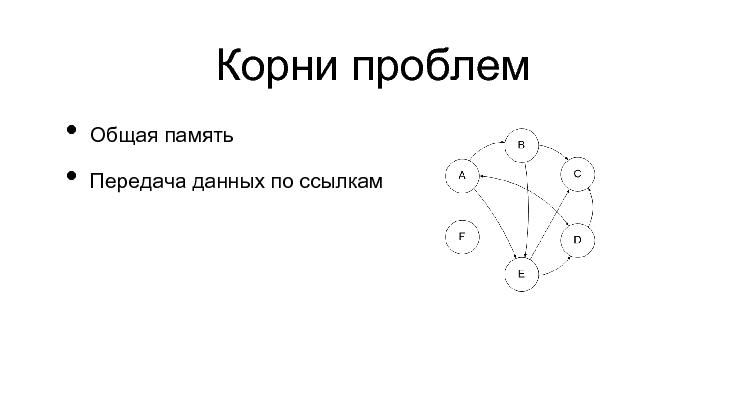
Web-подход → «пускай течет, скоро прибьем» → не работает. Здесь такого не будет, клиенты подключенные часами, днями и даже больше. И необходимо, чтобы ваш код код работал эффективно, не утекая, неделями. Erlang решает эти проблемы радикальноErlang оказался платформой, которая, на удивления, радикально решила эти проблемы, и практически полностью закрыла те проблемы, про которые я говорил. Это было сделано на 90 % из-за его концепции процессов. Процессы
Процессы в Erlange, это что-то типа тредов, в обычных системах. Они легковесны, они гораздо меньше места занимают, и самое важное — они абсолютно изолированы. Каждый процесс в Erlange, это такая коробочка, из которой ничего наружу не вытекает. И мы точно знаем, что вся память, которая есть в системе, гарантированно принадлежит какому-то процессу. Не может быть данных вне процесса. То есть всегда, если есть какой-то гигабайтный кусок памяти, вроде бы ничейный, но мы знаем, что за процесс им владеет и можем его прибить, чтобы эти данные освободить.
Ну это тонкости реализации, а на самом деле эти бинари можем отследить всегда. Они исследуются.
Мы знаем, процессу известно, на какие бинари и какого размера он ссылается. Поэтому, что у нас получается: все данные, которые есть в системе, хранятся исключительно внутри перечислимых процессов. Можно перебрать все процессы в системе, чтобы узнать, кто сожрал всю память, и прекратить это издевательство над системой. Все данные хранятся внутри перечислимых объектов Следующая особенность процессного подхода к организации данных внутри и потоков выполнения, заключается в том, что ошибки которые возникают, жестко ??? процесса. Если у нас есть ошибка, которую мы не обработали, которую мы не захотели ее перехватывать, мы решили, пуская она сыпется дальше, нас не интересует ее судьба, это фатальная ошибка, наш процесс завершается. И что самое главное, это очень-очень похоже на освобождение, уничтожение обьекта, потому что это известная по времени процедура, то есть мы знаем, что раз ошибка возникла, то процесс все, прекратился. Это будет не через час, не через два дня, это будет прямо сейчас. И важно понимать, что процессы, которые заказали…, которые хотят следить за его состоянием, другие процессы, соседние, они получат об этом информацию, что их сосед умер. Обработка ошибок
Соответственно, в системе которая предлагается, в платформе, которая поставляется с этим языком, есть система супервизоров, готовые механизмы, очень отлаженный набор программ, в них практически не находится ошибок, ну то есть мне неизвестно, чтобы в них находили ошибки за последнее время, они стабильно работают и позволяют вам рестартить ваши процессы. Зачем это нужно? Например у вас есть один из самых важных процессов в системе, это демон, это процесс, который слушает сокет. Он закрепился на сокет, и принимает соединения от системы. Вы можете быть уверены, что он то будет работать гарантировано, иначе вся ваша система вся может отвалится (???). Вот если он отвалился, уже нет смысла ваш сервер терзать. Слежение за процессами
К сожалению, я не смогу показать на своем ноутбуке, у меня нет переходника, но я хотел бы показть такую вещь, как app monitor. Это поставляющися, опять таки с платформой механизм, который позволяет вам графически, посмотреть список всех процессов, которые есть у вас, с их деревом. То есть мы можем… , это очень полезная вещь, когда вы можете видеть, что к вам приходит пользователь, у вас создался объект под него, он запросил какие-то ресурсы, под них просто залез (???) в какие-то процессы… Пользователь уходит, процессы остаются — фактически это утечка процессов, а с помощью app monitora, все это видится очень наглядно. Но, к сожалению, не покажу вам. :( В Erlang настоящее горячее обновление кодаА еще в эрланге есть, наверное единственное из всех существующих платформ, настоящее, горячее обновление кода. Выглядит это так — клиенты не отключаются, они продолжают работать, в случае с видеостримером, они продолжают получать видео, в случае с онлайн-играми не теряется соединение, а код уже обслуживает новый. Без отключения клиентов! Других систем, которые позволяют такое делать я не знаю. Какие результаты использования Erlang?И что же в итоге получилось, после того, как я решил воспользоваться эрлангом для создания своего сервера? Получился наш видеостриминговый серве Erlyvideo, которые сейчас находится в двойке-тройке лучших, в своей области, по набору реализованных фич, по скорости развития, по стабильности и эффективности. Erlyvideo:
Например, совершенно нормально обслуживает тысячи клиентов с одного сервера, сейчас стоит в продакшне у BD (???) и работает. Оказалось, очень эффективно и просто, за счет динамической типизации языка, которая естественно, динамическая, потому что мы не можем узнать, что это за другой процесс, поэтому все общение между процессами сводится к обмену сообщениями. Поэтому этот язык… можно говорить о динамической типизации этого языка. Поэтому получилась очень удобная инфраструктура для плагинов, которая также очень активно развивается. А ведь это очень болезненная тема для любого продукта, как грамотно выстроить систему плагинов. Очень непонятно, где сделать эти места, где можно этот плагин втыкать.
ВыводыЗадачи потокового видео имеют специфику, отличающую их от веба:
В итоге, какие же выводы можно сделать из применения Erlanga для этой задачи? Задачи передачи потокового видео в интернете, имеются свою специфику, которая очень сильно отличает их от веба. И к сожалению, многие решения обкатанными и надежными, и такими понятными… и кажется, что вы легко найдете для них программистов, несут в себе, в своей структуре, корни проблем, которые изначально пресечены в Erlange. У вас не будет этих проблем, потому что… просто в силу специфики органиазции кода. Поэтому в задачу обслуживания statefull клиентов, эрланг вписывается очень хорошо. И, практическое применение, показало крайнюю эффективность этого выбора. Применимость erlangНу понятно, что ниша потокового видео это достаточно узкая вещь, этих продуктов всего штук пять на рынке, и в принципе, этого наверное достаточно. Нет смысла писать другой сервер потокового видео на эрланге.
Однако, у него есть другие ниши применимости, например, на том же эрланге сделан самый лучший сервер Jabbera, это ejabberd, он настолько крут, что вот в яндексе, например, несмотря на жуткую антипатию к эрлангу, решили применять его, да, Яш? Сильно Гриша не любит Эрланг (bobuk)? Он очень ругался, плевался, но выбора у них не осталось — это говорит очень многое о продукте. Также, например, доистоверно известно, банки делают системы банковского процессинга. Я не знаю, конечно, какие именно детали, детали конечно не раскрываются, но я знаю, что у того же Приват-банка, есть еще ряд компаний, переводящих свои системы долгоживущего процессинга на эрланг, потому что им оказывается это удобным. Ну и конечно, онлайн-игры. Ко мне регулярно обращаются люди, после нашего успеха с раскручиванием топовой вконтактовской игрушки, то есть обращаются люди «нам бы сделать, чтобы у нас работало хорошо и удобно». Я смотрю на их проблемы, и понимаю, что им стоит реализовывать свою игрушку на эрланге, скорее всего. Потому что бизнес-логики не очень много, но она очень специфичная, и все те проблемы, которые я описывал, они соскребают использую обычные технологии, рельсы там, или джаву. И вот даже есть онлайн-реализация покера на эрланге.
Вопросы?Так что, в целом, у меня наверно все, вот такой вот доклад получился. Если у вас есть какие-нибудь вопросы, я с радостью на них отвечу.
В nginxe, горячего обновления кода — именно кода, не существует. Там есть горячее обновление бинарников. У вас стартует новая версия кода, биндится на старые сокет, при этом, сохраняя в памяти старый, если что-то пошло не так, и оно начинает обслуживать новых клиентов. И очень важно — что под теми клиентами, которые оно обслуживает прямо сейчас, вы не можете менять код. Ну потому, что написан на Си, и нет механизмов подмены байт-кода… на таком уровне. Поэтому то что сделано в nginxe, в nginxe сделано очень хорошее решение, прекрасно годится для сотен тысяч запросов в секунду, когда у нас их очень много, и ничего страшного — когда старые запросы работают со старым сервером, а новые уже будут новым сервером обрабатыватся. Что же касается плохого апдейта кода в ejabberd, ну, надо понимать, что это инструмент. Т.е. эрланг — это инструмент, единственно — который дает такую возможность и будете ли вы ею пользоваться эффективно, или не будете ею пользоваться — это уже решение программистов. Да, есть некоторые места, где обновлением кода пользоваться настолько неудобно, что проще просто на это забить и порты открытые дисконнектить. Тем более, что в условиях обслуживания через интернет, надо понимать, что дисконнект клиента это совершенно нормальная ситуация, любой statefull socket рвется … гарантированно рвется очень часто, это естественная ситуация. Поэтому, наверное не без этого, что, видимо, проще забить, чем использовать те механизмы, которые есть. Однако, если у вас есть среда, которую важно поддерживать, которую вы сами менеджите, вам очень важно, чтобы у вас было постоянное соединение, вы получите необходимую надежность, о которой я говорил.
Вопрос обновления кода он такой, надо понимать, в какой точке обновляется этот код. В случае с Эрлангом, псевдофункциональный, или в случае с Лисп, который функциональный, все это становится просто, просто мы на хвостовом вызове меняем модуль, из которого все это вызываем, вот и все. Какие еще вопросы есть?
По поводу утечек. Имеется в виду, что если, например, у вас используется Wowza, как, например, у моих клиентов, и утекает что-то, то очень сложно понять, что именно утекает и какие именно данные утекают. Не знаю, может быть в Java и можно перебрать все объекты в системе, которые зарегистрированы, но отследить граф, вот этот вот, очень сложно. В случае с эрлангом, все это становится гораздо проще — мы получаем список процессов, смотрим, кто из них памяти отожрал, намного больше, и мы моментально лоцируем утечку памяти. Когда мы узнаем, какой именно процесс утек в памяти, далее, в силу опять таки специфики немутабельности данных в эрланге, мы моментально выясняем причину этой утечки. Это настольно легко лоцируемая проблема, что это фактически снимает ее с какого-либо рассмотрения.
Это все достижимо, именно в связи с полной изоляцией данных, данные гарантированно находятся в каком-то процессе.
Да, потому что они полностью изолированы.
Ну да, я про это и сказал, ошибки — их не всегда ловят. Концепция, которая не всегда работает. Let it crash, про который вы упомянули, это концепция, что в эрланге принято писать код так, чтобы он описал happy path, правильный путь выполнения. Нет смысла обрабатывать ошибку. Зачем вообще обрабатывают ошибки? — Чтобы зачистить все ресурсы. Т.е. мы попробовали, а в файле какой-то мусор, не то, что мы хотим, надо аккуратно остановится, файл закрыть, буфер, который мы под него выделили, это все не забыть, это все надо аккуратненько, за всем надо следить. В случае, когда у нас все данные, жестко закрепленные внутри процесса, мы файлы читаем — там вот такие-то данные должны быть, нет → а, все! Нет смысла дальше читать, просто мы падаем, валимся... Этот подход несколько тяжеловат, в плане разработки, что мы просто видим, что у нас какая-то ошибка пролетела, нам не всегда понятно, почему данные убитые. На практике оказывается, что битые — ну и битые, ладно, зато у тебя код занимает не как я приводил пример с Javой, весь этот код, который я привел, это была проверка ошибок. А тут ты пишешь код, которые не проверка ошибок, а код, за который тебе платят деньги — никто не будет платить деньги за проверку ошибок, они мало кого интересуют сегодня. Если ты конечно, не DLS (???) программируешь.
Они прекрасно шедулятся по ядрам, runtime система прекрасно используется все ядра, которые у вас есть. И в силу того, что нигде и никто не держит на них никаких поинтеров, их можно перебрасывать спокойно, они работают параллельно на разных ядрах. И я часто делают тесты, и постоянно вижу одну и ту же картину, что загрузка процессора абсолютно линейная, в зависимости от количества клиентов. Когда система последовательно выходит на второе, на третье, на пятое ядро, на восьмое ядро, загрузка линейна, ровно линейна. Значит эта рантайм система настолько эффективна, что обслуживание процессов на соседних ядрах никак и никому не мешает.
Да, но…
Да, но важно понимать, что в случае, как было в двенадцатом релизе Эрланга, такой картины мы уже не увидим, из-за единого глобального мьютекса, которого уже давно нет.
Ну я бы сказал, что это проблема, проблема этой библиотечки.
Ну, далеко не все, что входит в стандартную поставку, отвечает стандарту качества, заданному Эрикссоном. Речь шла о том, что есть некоторые библиотеки, которые так устроены, что они не целиком и полностью живут внутри этого эрланга, и в итоге, при падении процесса, из-за плохо написанного кода они не зачищают все ресурсы. Могу сказать например, что когда я делаю свое Erlyvideo, я слежу за тем, чтобы следить за каждым клиентом, который захватил какой-то ресурс, чтобы отследить его утекание. Например, есть такой объект, это поток, который поток видео. В нем есть таблица клиентов, которым надо отослать видео. Нам приходит видеокадры, скажем, откуда-то, и нам надо по всем клиентом все это раздать, по всем которые сейчас подключены. Очевидно, что когда клиент подключается, тот процесс присылает сообщение «подпиши меня», говорит свой бит, я подписываю его, и сразу подписываюсь на событие о его смерти, если клиент умирает, мы должны его из таблицы удалить. Такие вещи конечно надо отслеживать руками, о том, что какой-то потребитель умер. Но надо понимать, что в итоге, такой подход дает нам наверное единственный язык, в котором совмещены вместе и сборка мусора, и гарантированное время жизни объекта. Потому что, языки с классической сборкой мусора, будь то Java или там Ruby, или Objective C, у всех у них, мы никогда не знаем, когда же объект будет освобожден. Мы больше не держим на него ссылку, ну во-первых, мы не знаем, может кто-то еще держит на него ссылку? Ну и даже, когда он уже не нужен никому, когда еще до него доберется сборка мусора? В случае с Эрлангом у нас есть гарантированные алгоритмы, когда мы знаем, что да, этих данных точно больше не существует. И ID того процесса у нас уже не валиден. Такая вот вещь.
Да нет, не было. Да я еще к Ruby привык, что у нас нет такого, нет жесткой типизации. Могу сказать, что для задачи стримингового видео нет такой необходимости. Наверное, можно сказать, что какую-нибудь жуткую логику для обработки банковского платежа я бы на чем-то другом начал писать, потому что было бы неудобно. Но в этих задачах точно нет никакой проблемы, потому что вход настолько упрощается, что теряется жесткое желание иметь хоть какую-то статическую типизацию, потому что очень важно понимать, что подход с pattern matching-ом, который применяется в Erlang, там немного по-другому реализована внутри структура функций, вот этот подход, он позволяет акцентировать твое внимание не на типах, которые тебе приходят, потому что они на самом деле ни о чем не говорят, а на их содержимом. Вот как на Java — у нас есть функция, у нас есть ее какое-то описание, что вот, в данной функции мы ожидаем в этой функции ID, даже id3v1 (см. вышеприведенный пример кода на Java), а дальше мы проверяем, что в зависимости от одного его содержимого будет одна ветвь кода, в зависимости от другого — другая, и в общем, я не вижу каких-то преимуществ от статической типизации.
А может у меня какой-то профессиональный навык (???), поскольку прочитывая тысячи строк кода на С, все это становится уже не так болезненно.
Ну да. Тут что спасает, хорошо написанный код, он в заголовке своем несет то, что он ожидает. Т.е. у нас уже в заголовке функции будет написано, что здесь ожидается такой-то рекорд, с такими-то полями. Мы уже на самом деле понимаем, что это event такой-то, и мы его ждем.
Ну да, получается, что мы в самом начале кода акцентируем внимание на главном. В итоге получается, что с этим проблем особых не было.
Ну, «блокнот» в принципе неприменимое средство для кодирования, но по сути, я пользуюсь TextMate-ом, это по сути, блокнот с подкрашиванием. Вопрос примерно такой же, как «Есть ли среда для Ruby on Rails?». Они вроде как есть, но я не понимаю, зачем ими пользуются, они вроде как не работают. В динамической типизации вы никогда не знаете, где и что у вас находится. Ну есть вроде для Eclipse что-то…
Это просто никому не нужно. Никому не нужно.
Надо понимать, что ценность IDE, она резко падает, потому что… IDE она чем хороша — тем, что вы можете в ней много и часто писать код, либо рефакторить… Ну наверно, да, для рефакторинга это было бы удобно. Я пользовался рефакторингом в Eclipse и Idea, и не могу сказать, что этого мне сильно не хватает. Вот сразу еще вопрос, который часто задают — «Где искать программистов на этом языке?». Могу сказать сразу, что проблем с этим нет никаких. Когда мне были нужны люди для Erlyvideo, я находил их в течении дня. Любой человек, который разбирается в Java или там в C, его квалификации выше крыши для того, чтобы неделю начать писать код, даже меньше. Когда я начал писать на Erlange, я с утра взял книжку, а к обеду написал код, который работал, который коннектился по RMTP, и что-то там с ним обменивался. А через неделю я уже делал коммиты в чужой код, который я видел первый раз в жизни (на Erlange). Никаких проблем с этим не было. Вот этот язык, несмотря на его, несколько чуждый синтаксис, на самом деле он имеет очень примитивный синтакис, очень простая семантика, она в тысячу раз проще, чем в С, Java и чем-то еще, и просто немножко отталкивает его другая структура мышления, которая в нем заложена, другая семантика, она просто другая, она гораздо проще, чем в любом другом языке.
В ErlyVideo что плохо?
Проблемы все связаны… Ну вот, например, элементарно не доделана выдача на iPadы, с этим эппловым стримингом на самом деле большие проблемы, потому что протокол заявлен как открытый, а на самом деле это закрытый, обычный проприетарный протокол, ничем не отличается от RTMP. Преимущественно все связано с закрытостью протоколов, т.е. с тем, что люди, которые пишут альтернативные серверы уже тот путь, по которому сейчас иду я, этим путем они конечно не будут делится никогда, потому что это большое value. Напримет, тот же RTMP, который у Adobe закрытый, несмотря на наличие спецификации, спецификация — ложь, и в ней обман, намеренный обман, это закрытый протокол и они никогда его не откроют полностью, и конечно же проблемы возникают именно с какими-то непонятностями в том, как именно пользоватся RTMP. Ну потому что это непонятно, а дизассемблировать флеш или флешсервер — это с ума сойдешь. Это основные проблемы. Что же до (???)ности, у того же RTMPD она выше, но это никак не сказывается на реальности использования, потому что канал заканчивается раньше. Даже двухгигабитный.
Только для аудио есть механизм. Но вообще конечно, поток-сервер видео и аудио не должен заниматься транскодированием. Это задача других инструментов, по той причине, что транскодирование это задача безумно, безумно, безумно ресурсоемкая. Так, нас уже заканчивают.
Ну писать транскодер на эрланге это такая глупая задача, посколько там, где работает числодробильная арифметика, там будет раз в сорок медленней работать, в силу того, что все int-ы это объекты, которые аллоцируются в куче, динамически. Есть два способа включения библиотек в эрланг, и надо понимать, что оба из них могут привести к полному краху системы потому что они включают код на С, и вы вносите баги, которые есть в этом коде, про которые я говорил. Если ваша библиотека параллелится по памяти, то вы получите все те проблемы, про которые я говорил. Есть два способа. Один из них пригоден для библиотек, занимающихся быстрыми вещами, не блокирующими, другой — более сложный и более муторный, приходися применять запрещение (???) библиотек, которые могут заблокировать глобальный lock интерпретатора. Но эффективней все это делать через внешние программы, тогда у вас сохранится вся та надежность, про которую я говорил. Примечания
Репликация: База Знаний «Заказных Информ Систем» → «Разработка видеохостинга на Erlang (Максим Лапшин на ADD-2010)» Любые правки этой статьи будут перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion». |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
