Аннотация
- Докладчик
- Владимир Бахов
Непрерывная интеграция — это высокотехнологический инструмент, неотъемлемая часть качественной бездефектной машины по производству ПО. Средства и методология непрерывной интеграции программных приложений хорошо развиты на сегодняшний день. Однако разработка сложных баз данных существенно отличается от разработки приложений. Зачастую неприменимы классические методы непрерывной интеграции: использования системы контроля версий, автоматической сборки скриптов наката релиза, системы автоматизированного тестирования.
Тем не менее, agile парадигмы о раннем, постоянном и автоматизированном тестировании качества сборки могут найти свое полноправное место и в разработке баз данных. Презентация посвящена методологическим и практическим особенностям построения CI для Oracle базы данных.
Видео
Для этого доклада нужен подкаст (аудиозапись)?
Презентация
Примечания и отзывы
- Докладчик
- Владимир Бахов
- Компания
- AT-Consulting
Данный доклад на камеру пришлось снимать тоже мне. Докладчик, к сожалению, проявил максимальную активность (из всех, кого мне довелось снимать) при перемещении во время доклада, что отрицательно сказалось на восприятии доклада.
Рациональным зерном является то, что
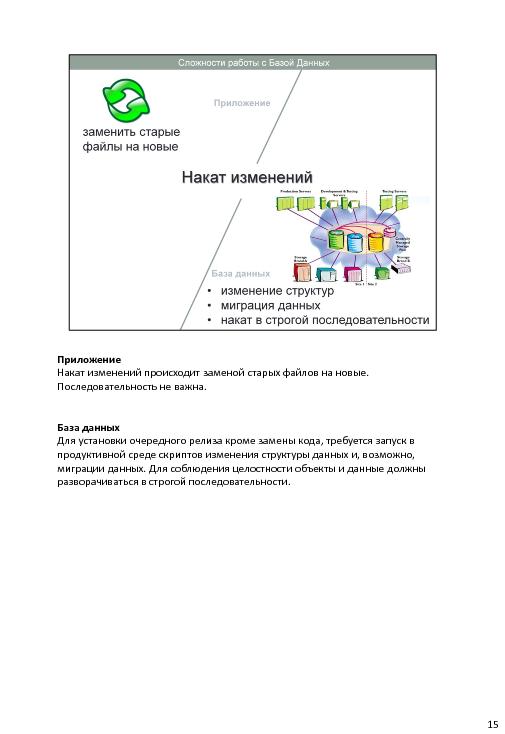
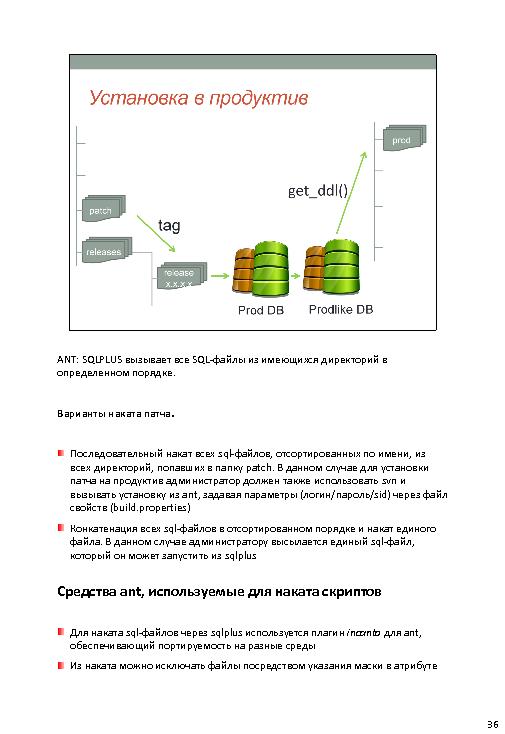
- нужно запретить ручные правки в базе данных в процессе разработки, изменяя только скрипты;
- в той части разработки, которая касается БД, тоже использовать Continuous integration
Что не понравилось в докладе:
- Используемые термины «накат изменений», «продуктивная среда», «продуктив».
- Первоначальная структура таблиц в скриптах и данные не хранится, восстанавливается из первоначального дампа.
- Очень перегруженные слайды доклада.
Что понравилось:
- Идея Continuous integration к БД.
- Обязательное использование библиотеки для unit-тестирования PL-SQL-кода (используют utPLSQL)
- Использование средств мониторинга успешности/неуспешности очередной сборки.
- Автогенерация скрипта изменений в БД.
Неоднозначный, но полезный доклад для расширения кругозора.
- Непрерывная интеграция при разработке баз данных (Владимир Бахов, AgileDays-2011)
Пионер — относительно нас, мы примерно так со скриптами полного проноса или изменений работали лет 5 назад и ранее. Переход от ручного наката к версионным скриптам и постепенном накате изменений.
Но то, что сделано — работает. Народа было много, тема людям интересна.
Я все-таки позиционировал этот доклад к докладам о новом опыте, не столько потому, что мы впереди, сколько потому, что рассказывалось без вариаций о том способе, который они сейчас применяют, без связи с окружением мирового опыта. А сами они — работают одним способом.
Важно отметить, что доклад был не просто про установку изменений, а именно про непрерывную интеграцию и тестирование.
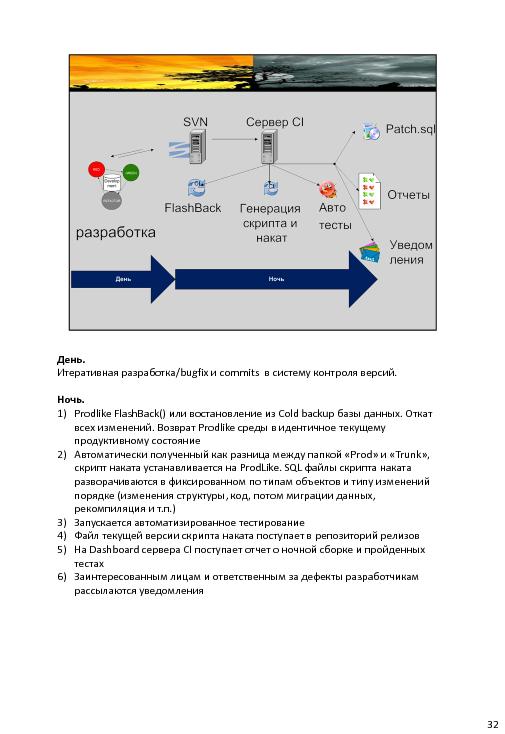
Для тестов они делают тестовую деревню на синтетических данных, а сами тесты делятся на 2 категории: легкие по commit и тяжелые ночью.
Заметки.
- Началось все как-то примитивно, когда был просто ручная сборка скриптов и накат, нет версионности БД, несоответствие тестовой и боевой по производительности и т. п.
- И вообще скриптовый build-инженер ушел в отпуск — жопа
- Я еще мяч между dba и разработчиков. Да еще когда поставка на площадку, где накатывают другие люди.
- Якобы все решает непрерывная интеграция. Я: На самом деле — совсем не все, то о чем он говорит — это просто наличие тестовых площадках, а непрерывная интеграция — про другое.
Стас Фомин:Собственно это
я говорил автору еще на этапе ревью. И впечатлил оного — после доклада он подходил ко мне, чтобы я посоветовал ему гуру непрерывной интерграции — я послал его к вам и Игорю Беспальчуку (сам был в полном мыле, общатся не мог), не знаю, дошел ли он до наших.
- Что есть БД — в ней много данных, надо накатывать изменения, делать миграцию и прочее.
- В общем, с БД сложнее, чем с веб-приложениями.
- Особенно откат на предыдущую версию. Например, drop table.
- Есть проблемы с продуктами, поддерживающими CI…
- 15 минут внедрения. потом решение — да, это можно.
- Что надо: svn + UTPLsql (сейчас у Oracle в sqldev что-то вышло)
- Задача первая — все менять скриптами.
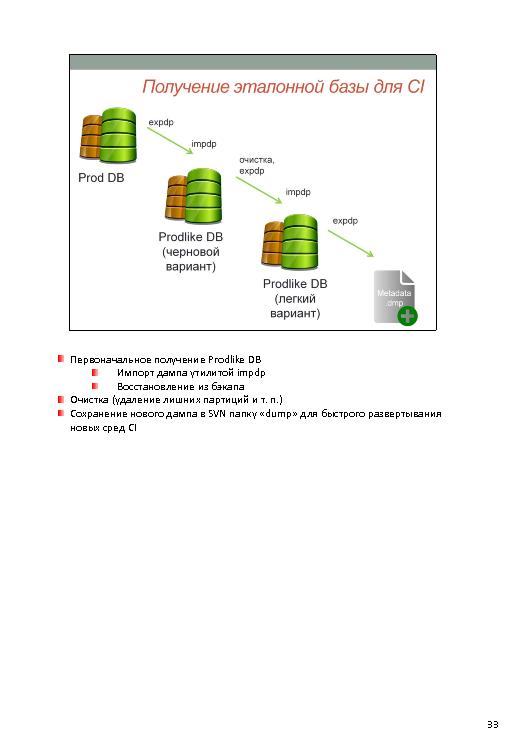
- Для начала — надо снять текущий слепок кодов проекта prod (по умолчанию исходных кодов нет). Снимают в директории по типам объектов. И именуют с цифрами для правильной сортировке.
- Есть trunc. А дальше — diff между trunc и prod. И накатываем. Продуктив один (хотя там можно по версиям, наверное). Специально добавляют какие-то скрипты и пишут их вручную. По вопросам — надеялись и это автоматом сделать.
- Урезанная продуктивная база для синтетического тестирования.
- Важны функциональные синтетические тесты.
- Поднятие локальной базы — для всех разработчиков. Важно быстро.
- Наивные вопросы из зала — а как бы сделать откат все-таки…
- Техника — diff, ant, hudson/teamcity. Тесты — легкие постоянно, тяжелые ночью. И авторассылка результатов тестов.
- Деревня для автотестов (синтетические данные).