Андрей Майоров, директор компании BYTE-force рассказал об удобстве использования иерархических структур данных в своих приложениях.
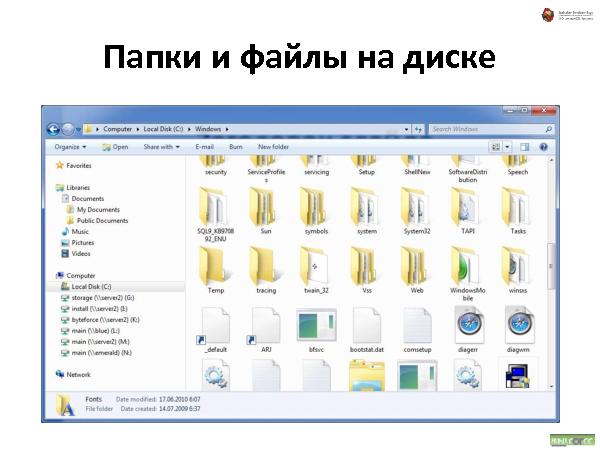
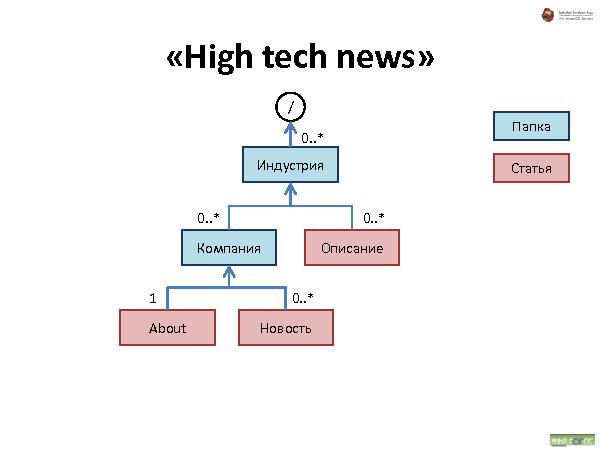
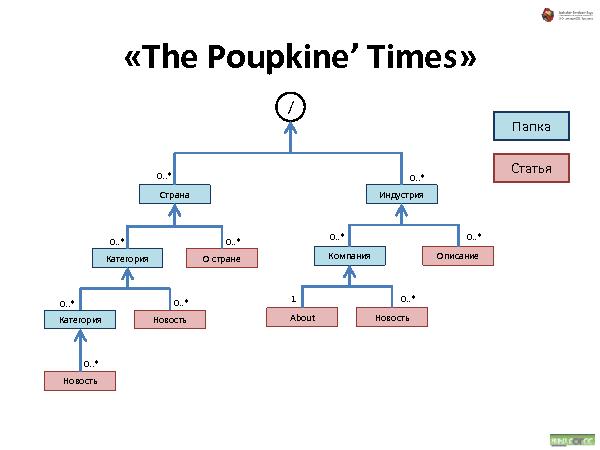
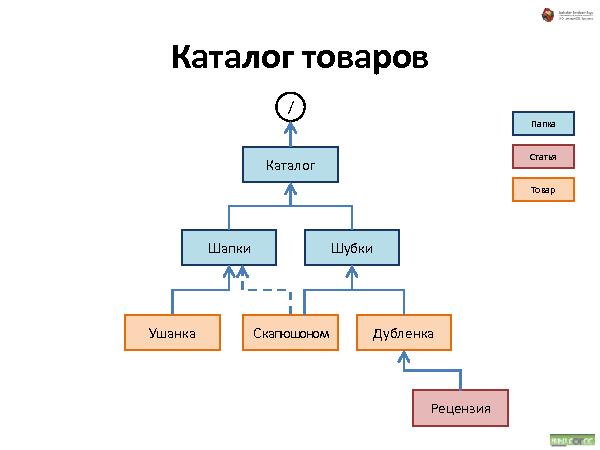
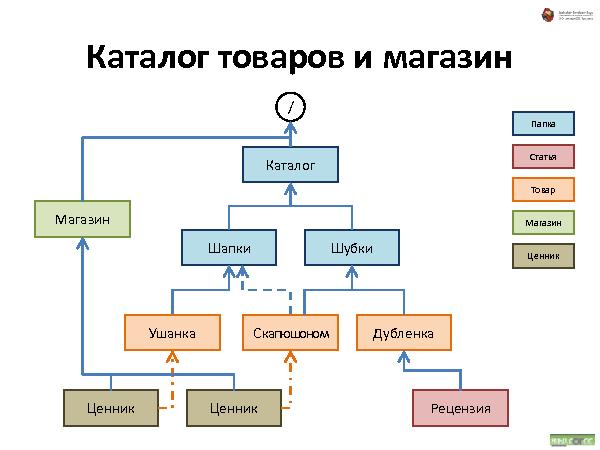
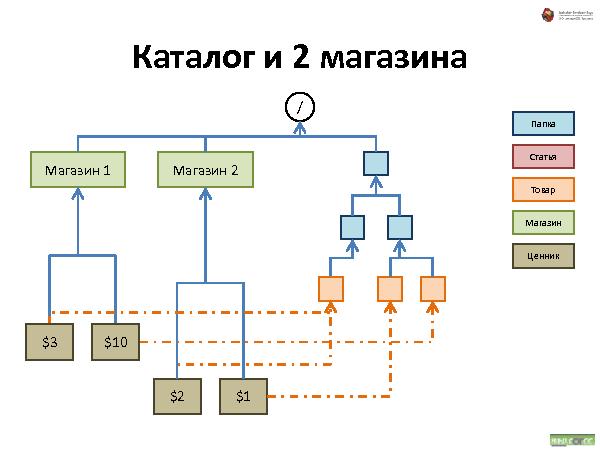
С иерархическими структурами данных сталкивался каждый пользователь компьютера: диски, папки, файлы — все это привычно и понятно почти каждому. Что если пойти дальше и применить ту же концепцию иерархической организации для произвольных объектов вашего приложения? Любой объект — это аналог файла на диске. Объекты можно класть в контейнеры — в «папки». Контейнеры и сами по себе являются объектами, и их тоже можно положить в другие объекты, и так далее. Получается глобальная структура объектов, которая не только хорошо понятна пользователю на уровне концепции, но и очень устойчива к изменениям требований. Зачастую для добавления нового функционала в систему перепроектирования не требуется.
Об удобстве иерархических структур данных (Андрей Майоров на ADD-2010)
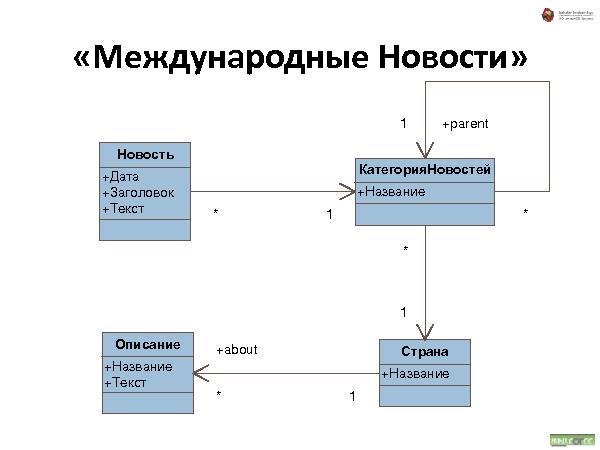
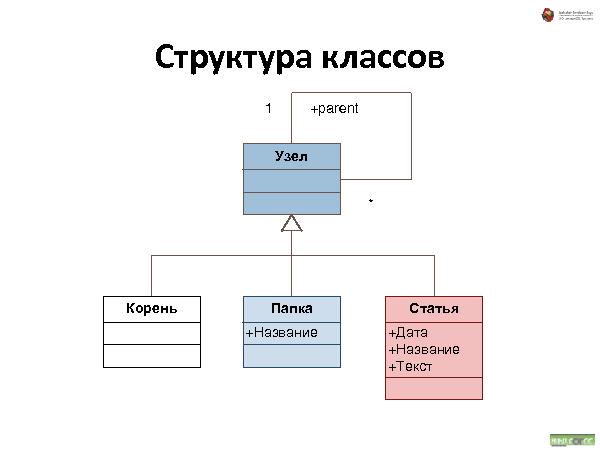
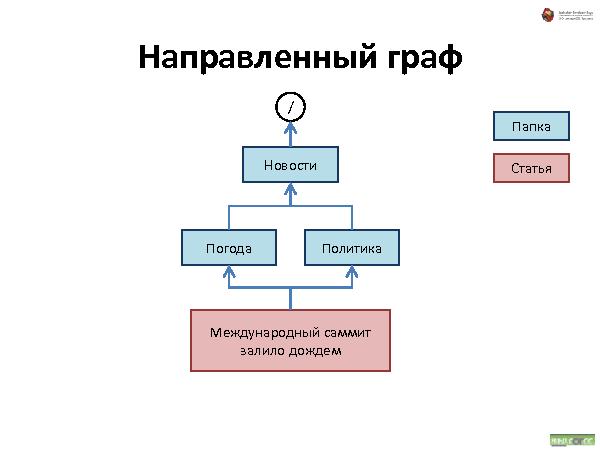
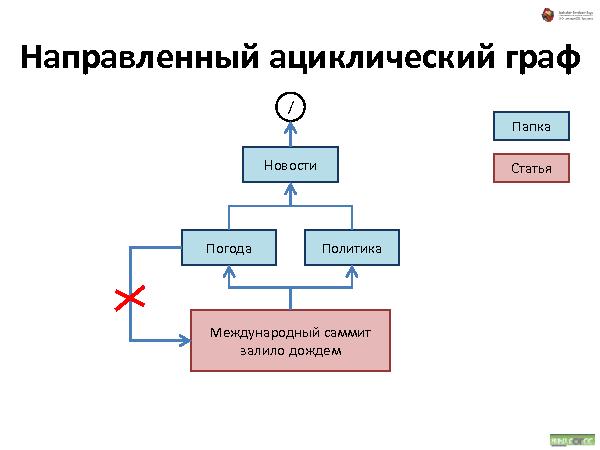
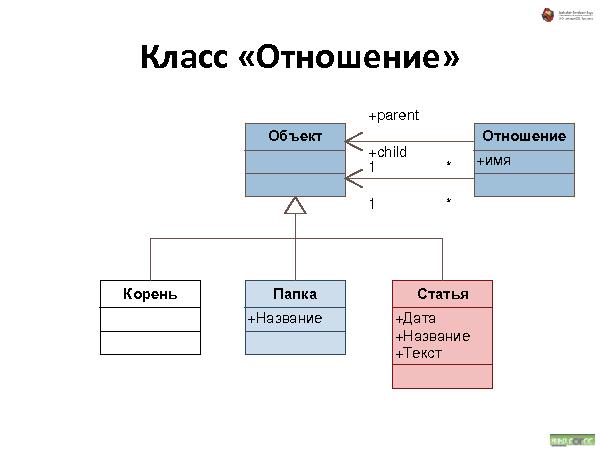
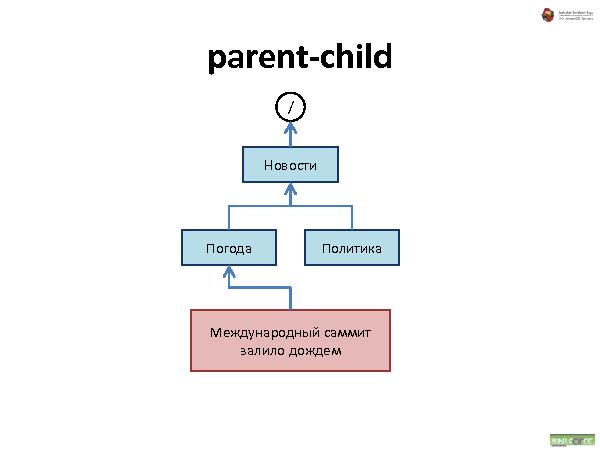
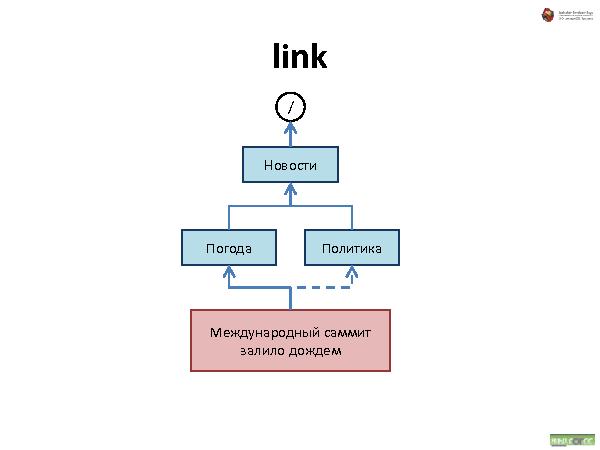
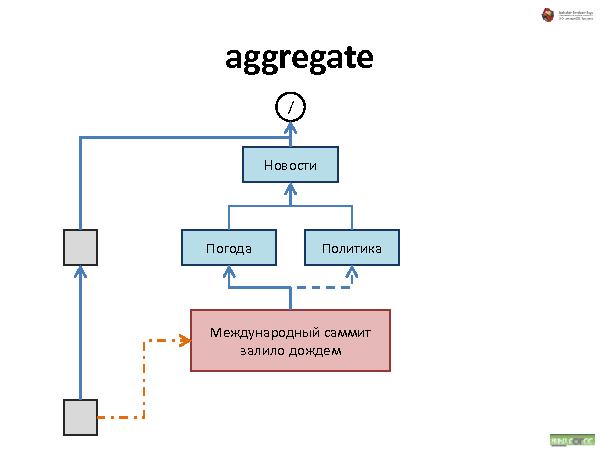
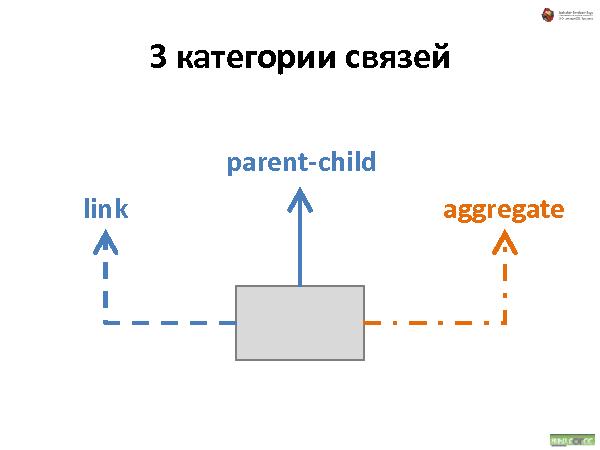
Была представлена методология хранения данных, которая состоит из трех видов связей:
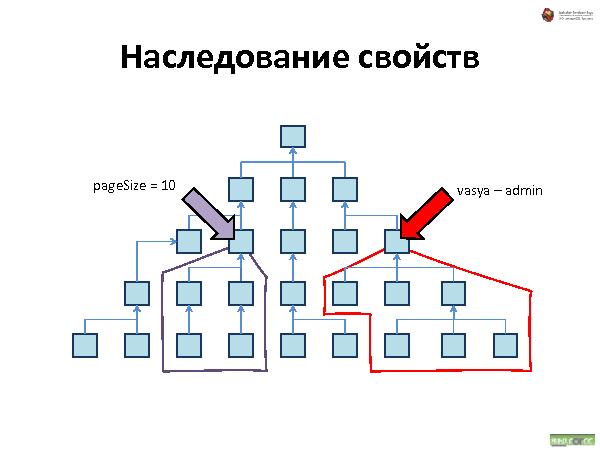
Наследование — все свойства наследуются. При удалении — удаляются.
Аггрегирование — тоже, что и наследование, но свойства не наследуются.
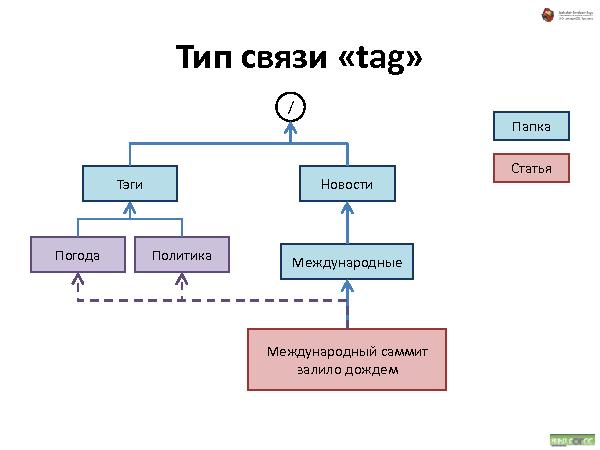
Link — просто ссылка.
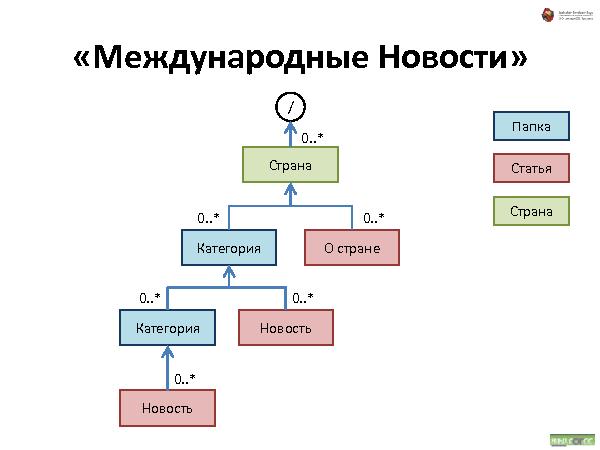
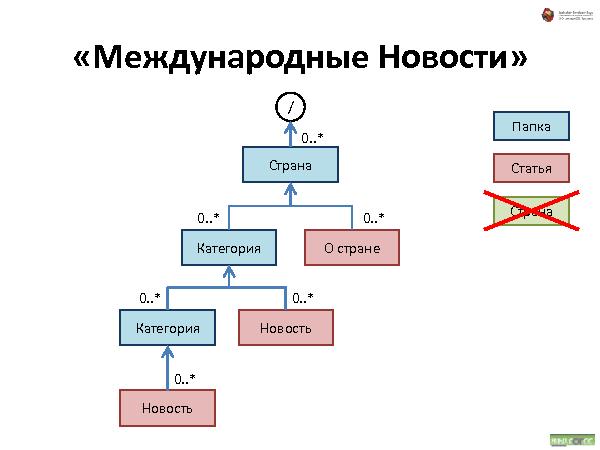
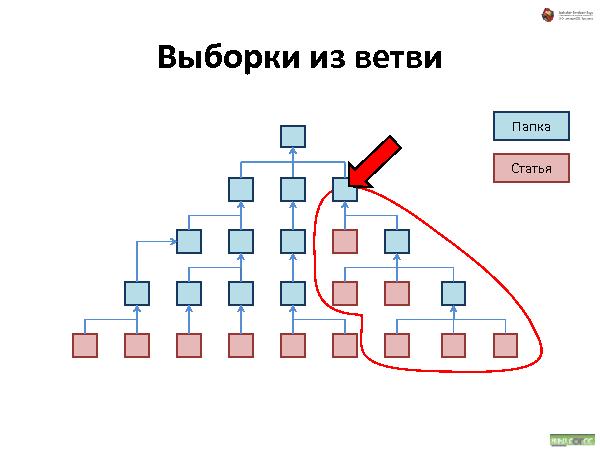
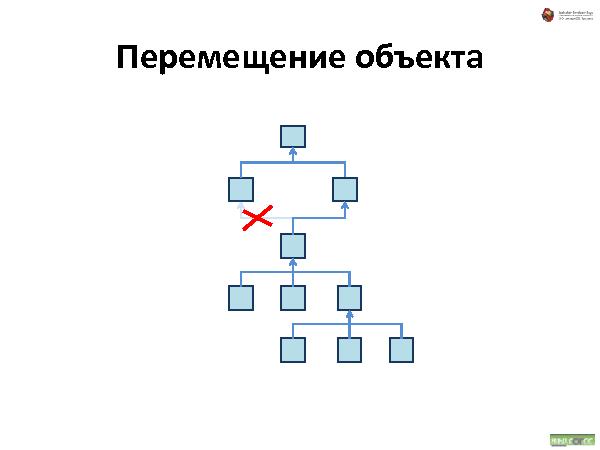
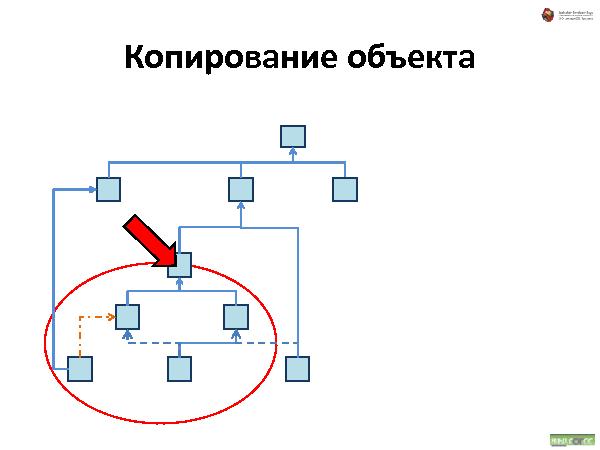
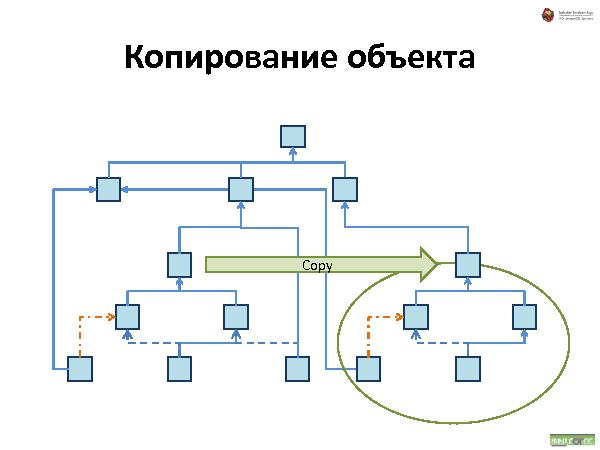
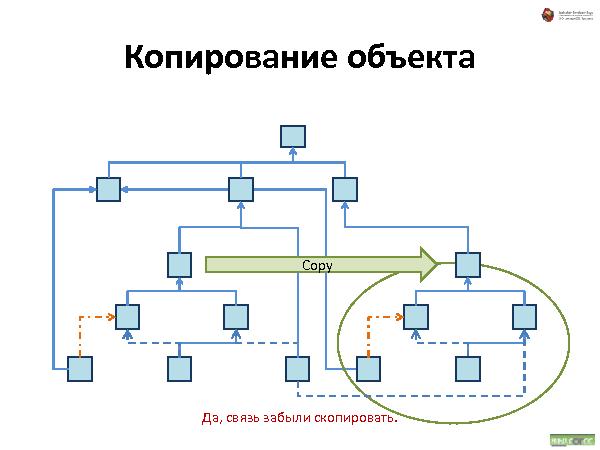
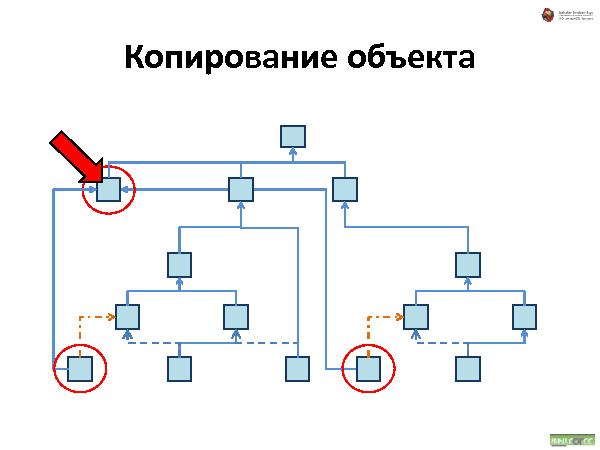
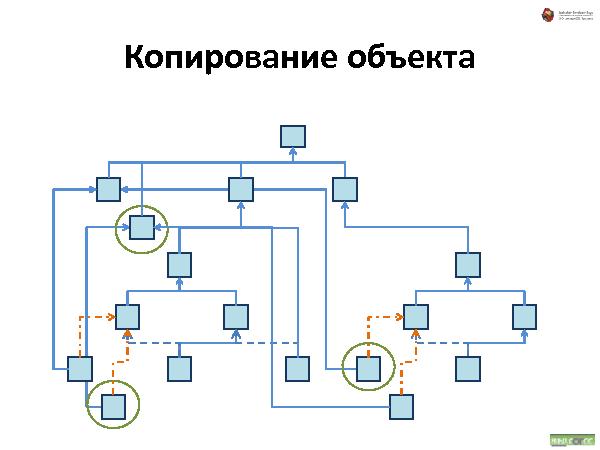
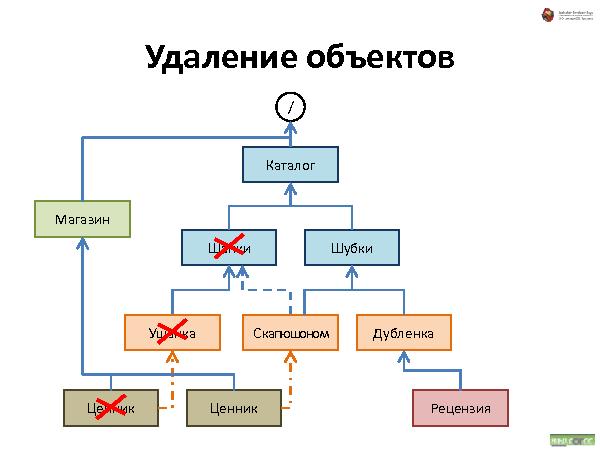
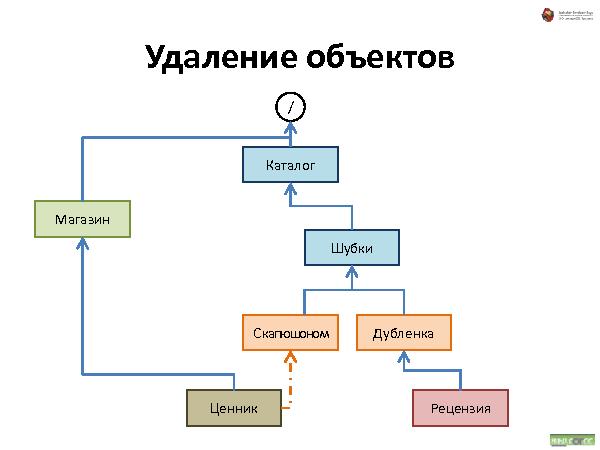
Далее была рассказана и проиллюстрирована работа с такой организацией данных. Что происходит при удалении, добавлении и перемещении.
Такая структура не подходит для больших объемов данных, зато хорошо работает для не очень большого объема данных, типичный пример — средний web-сайт.
Идя на доклад, я рассчитывал увидеть какие-то крутые структуры данных, но это была именно организация данных, без каких-либо алгоритмов, оценок, и т. д.
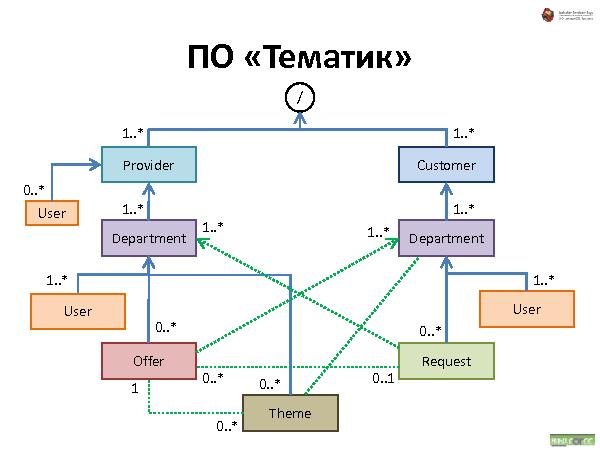
Докладчик предложил сообществу свой фреймворк SDF, который и умеет работать с данными таким образом.
Внимание! Эта статья была создана путем автоматического реплицирования из внутренней базы знаний компании Заказные Информ Системы. Любые правки этой статьи могут быть перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion».