
|
Персональные инструменты
Просмотры |
|
Персональные инструменты |
|||
|
|
|
Apache Hadoop (Владимир Климонтович на ADD-2010)Материал из CustisWiki(перенаправлено с «122-Hadoop-add2010»)
Короткая ссылка: 122-Hadoop-add2010 Содержание
Аннотация
ВидеоПодкаст
Презентация     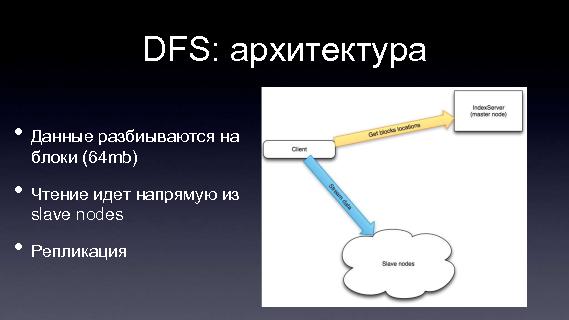    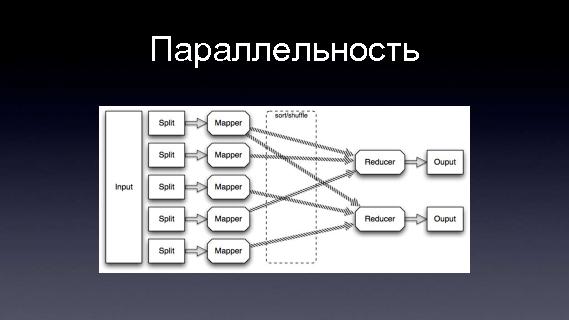    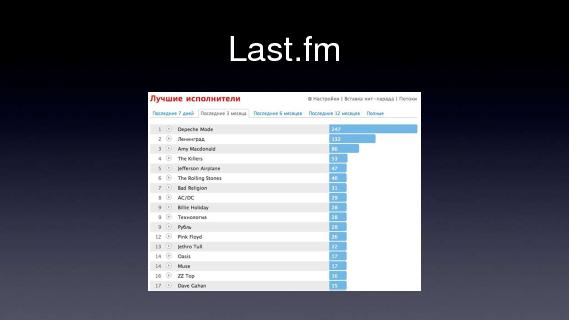      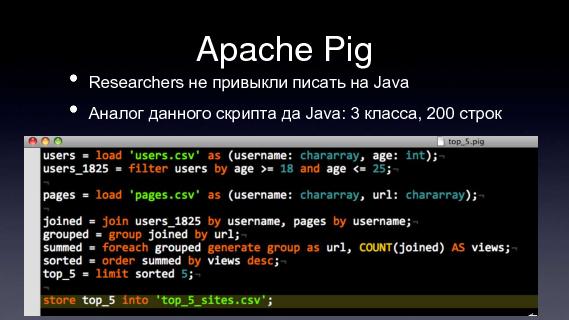       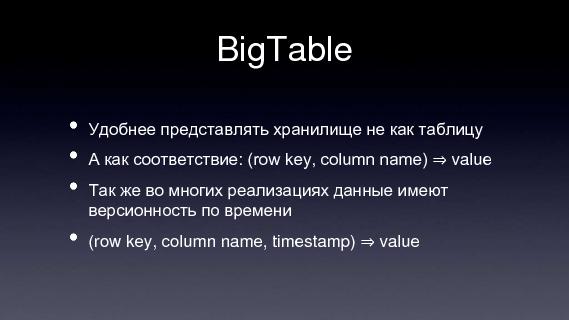         Стенограмма
SummarySummary
Собственно говоря, про что я вам такое сегодня расскажу. Так, ничего не видно, так что придется сегодня больше рассказывать, чем смотреть. Последнее время, за последние, скажем, лет десять, в IT в целом, стала проблема обработки большого объема данных. В первую очередь, она стала перед такими компаниями как Гугл, которая занимается поиском, и прочими компаниями. В общем, сегодня я расскажу, как задача решается. Как она решается в целом, что было придумано компанией Гугл, в 2003-2004 году и также про open-source реализацию этих способов обработки и хранения больших объемов данных, под названием Apache Hadoop. И также если останется время, я немножко расскажу про column-oriented databases, это базы данных, которые устроены немного по-другому, чем реляционные, и также про реализацию.
Объемы данных Итак, чтобы вы представляли, о чем идет речь, о каких объемах данных. Например, компания Facebook, всем известная, наверно у всех есть там профайлы, у компании Facebook в день появляется 40 терабайт новых данных — фотографии, посты, комментарии, опять же лог-файл просто — показы страниц и прочее. Что у нас дальше — опять же Нью-Йорская биржа, один терабайт транзакций в день, данные о транзакциях, покупки и продажи акций и прочее. Большой андронный коллайдер: это где-то сорок терабайт экспериментальных данных в день, информация о скорости и положении частиц и прочее. И для примера, чтобы вы представляли, что происходит в небольших компаниях, — компания ContextWeb это небольшая американская компания, в которой по сути работаю я, которая занимается онлайн адвертайзингом, совершенно небольшая компания с очень маленьким процентом рынка, тем не менее это 115 гигабайт логов показа контекстной рекламы в день. Причем это не просто текстовые файлы, это 115 гигабайт сжатых данных, т.е. на самом деле данных наверное сильно больше. DFS/MapReduceDFS/MapReduce
Возникает вопрос, что собственно говоря с ними делать? Потому что надо их как-то обрабатывать. Сами по себе такие объемы данных они никому не интересны и довольно бесполезны. Один из способов обработки таких объемов данных был придуман компанией Google. В 2003 году компания Гугл выпустила довольно известную статью про distributed file systems, как они хранят у себя внутри данные и индексы, данные о пользователях и прочее. В 2004 году опять таки компания Гугл выпустила статью, которая описывает парадигму обработки такого объема данных, которая называется MapReduce. Собственно как раз про это я сейчас и собираюсь рассказать, как это оно устроено в целом, и как это реализовано в платформе Apache Hadoop. Distributed FSТребования к распределенной FS
Distributed Filesystem — что это такое вообще? Какие задачи ставятся перед Distributed Filesystem?
DFS: архитектураСобственно говоря, как это реализуется. Здесь есть небольшой график, наверное его не видно, но в целом видно, да. Есть кластер из машин, которых много, на которых хранятся данные. Есть одна машина, которая называется master node, и которая координирует все. Что хранится на мастер-ноде? На мастер-ноде просто хранится таблица файлов. Структура файловой системы, каждый файл разбит на блоки, на каких конкретно кластерных машинах, храниться какие блоки файлов. Как происходит запись и чтение? Мы хотим прочитать какой-то файл, мы спрашиваем у мастер-ноды где хранятся блоки такого-то файла, он нам говорит, на какой машине хранятся конкретные блоки, и мы уже читаем напрямую из кластерных машин. То же самое с записью, мы спрашиваем у мастер-ноды, куда нужно писать, в какие конкретно блоки, в какие конкретно машины, он нам говорит, и мы записываем напрямую туда. А для обеспечения надежности, каждый блок хранится в нескольких экземплярах, на нескольких машинах. Этим обеспечивается надежность, даже если у нас выйдет из строя, скажем, 10% машин в кластере, скорее всего, мы ничего не потеряем. Т.е. да, мы потеряем какие-то блоки, но поскольку эти блоки хранятся в нескольких экземплярах, мы сможем опять таки и читать и записывать. 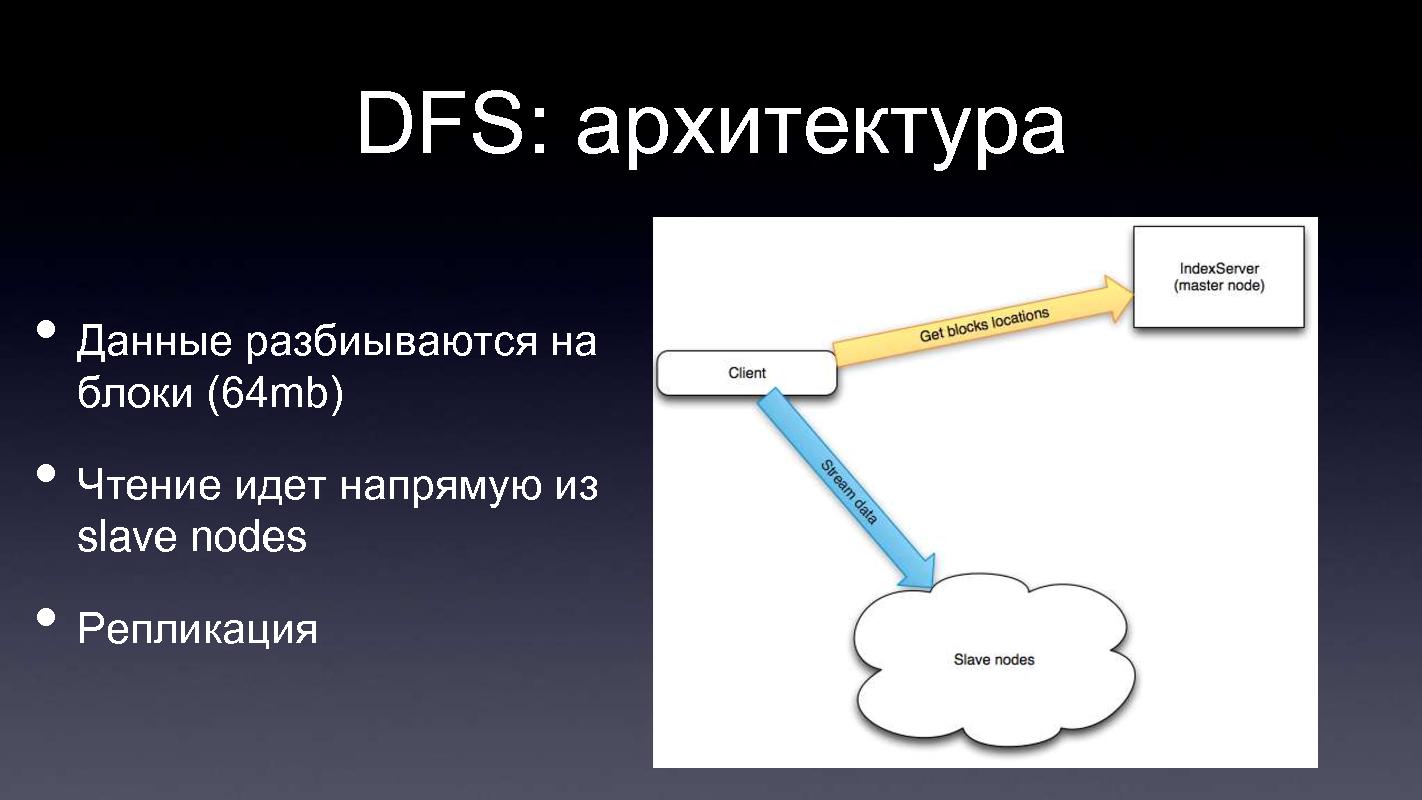
КонфигурацияКонфигурация
Типичная конфигурация, которая, например, используется у нас в компании. Чтобы хранить большие объемы данных, например, в нашей компании это 70 терабайт, которые мы регулярно анализируем, что-то с ними собираемся делать, это где-то сорок машин, каждая машина это слабенький сервер, если смотреть по индустрии, это где-то 16 гигабайт оперативной памяти или 8 гигабайт, терабайтный диск, никакого RAID, просто обычный диск. Какой-нибудь Intel Xeon, в общем, какой-то дешевенький сервер. Таких серверов тоже сорок, и это позволяет хранить такие объемы данных, скажем, сотни терабайт.
MapReduceMapReduce
input record ⇒ (key, value)
(key, {v1, ..., vn}) ⇒ output record
Данная парадигма применима к широкому спектру задач После того, как все файлы храняться на distributed файловой системе, возникает вопрос, как их обрабатывать. Для этого компанией Гугл была придумана парадигма, которая называется MapReduce. Выглядит она довольно странно. Не знаю, видно ли, что тут написано? Отлично! Выглядит она очень странно. Это обработка данных, в три операции. Первая операция… , у нас есть какие-то входные данные, например, набор каких-нибудь input record-ов. Первая операция, которая называется Map, которая по каждому input record-у выдает нам пару «ключ → значение». После этого, внутри, эти пары «ключ → значение» группируются, каждому ключу, когда мы обработаем все входные записи может соответствовать несколько значений. Группируются, и выдаются на процедуру Reduce, которая получает ключ, и соответственно, набор значений, и выдает уже, окончательно финальный результат. Таким образом, у нас уже есть набор каких-то input record-ов, например, это строчки в лог-файле, и мы получаем какой-то набор output record-ов. Выглядит все это достаточно странно, как какая-то узкоспециализированная вещь, как что-то из функционального программирования, непонятно сразу, как это может применятся на широкой практике. ПримерКак посчитать по браузерам (Facebook)
log record ⇒ (Browser, 1)
(Browser, [1, .., 1]) ⇒ {Browser, sum}
На самом деле, очень хорошо может применятся на широкой практике. Самый простой пример. Пусть мы компания Facebook, у нас очень много данных, .... ну просто логи показываем страниц на фейсбуке. И надо посчитать, каким броузером кто пользуется. Это сделать, с помощью парадигмы MapReduce довольно легко. Мы определяем операцию Map, которая по строчке в access loge определяет ключ-значение, где ключ — это броузер, а значение — просто единичка. После этого, остается сделать операцию Reduce, которая по набору броузеров и множеству единичек просто делает суммирование, и на выходе выдает для каждого броузера полученную сумму. Мы запускаем эту задачу MapReduce на кластере, в начале у нас много-много лог файлов, в конце у нас такой маленький файлик, в котором у нас есть броузер, и соответственно, количество показов. Таким образом мы узнаем статистику.
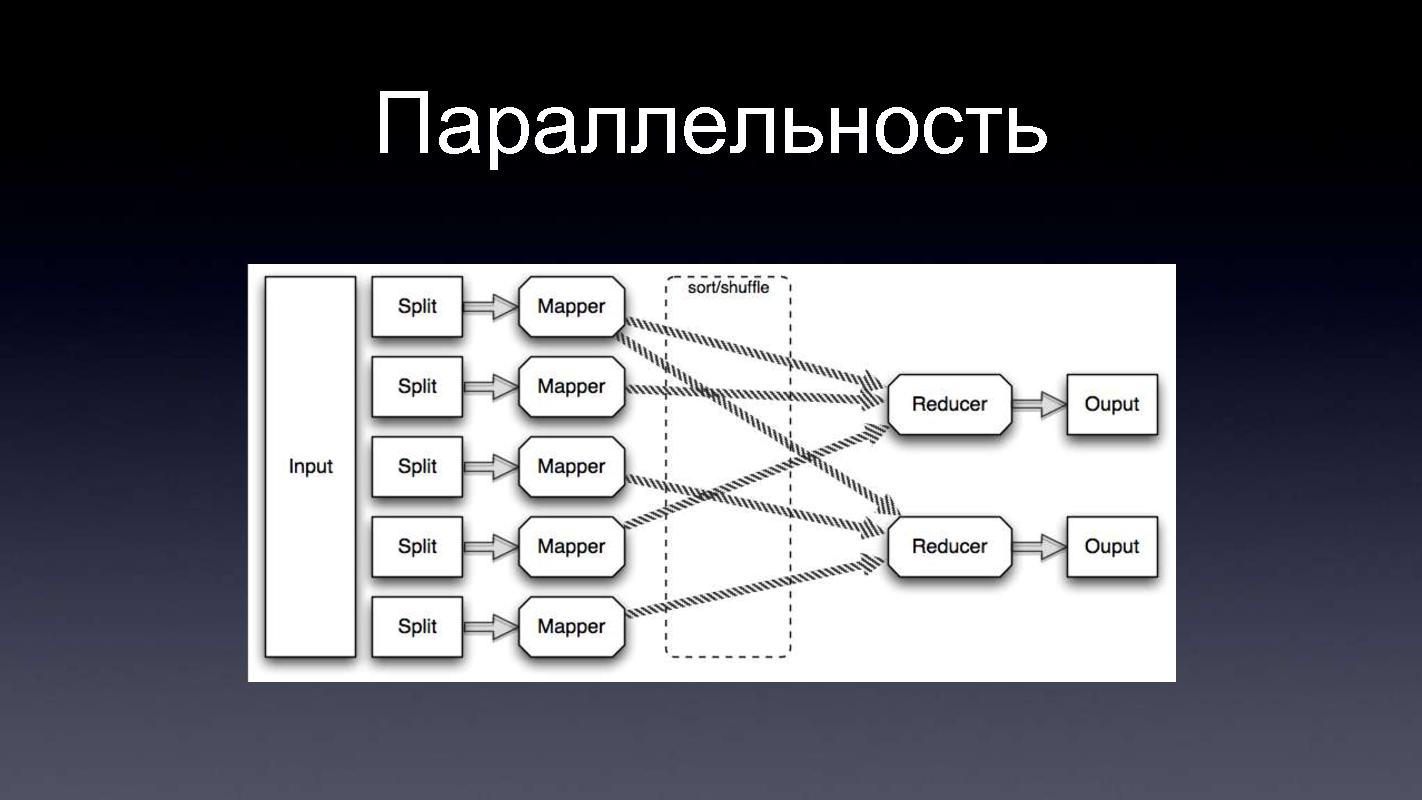
ПараллельностьПочему это хорошо, MapReduce? Такие вот программы, когда мы задаем Map и задаем Reduce, они очень хорошо параллелятся. Допустим у нас есть какой-то Input, это большой файл, или наборы файлов, этот файл можно разбить на много-много маленьких кусочков, например, по числу машин в кластере, или больше. Соответственно, на каждом кусочке мы запустим нашу функцию Map, это можно делать параллельно, все это запускается на кластере, по-тихонечку вычисляется, результат каждого map-а, внутри как-то сортируется, и отправляется на Reduce. То же самое, когда у нас есть результат какого-то Map-а, много каких-то данных, мы можем опять эти данные разбить на кусочки, опять таки запустить на кластере, на многих машинах. Благодаря этому и достигается масштабируемость. Когда нам нужно обрабатывать данные в два раза быстрее, мы просто добавим в два раза больше машин, железо сейчас относительно дешевое, т.е. без всякого изменения архитектуры мы получим в два раза большую производительность.
Apache HadoopApache Hadoop
Apache Hadoop — что это такое? После того, как Гугл опубликовал эти статьи, все решили, что это очень удобная парадигма, в частности, возник проект Apache Hadoop. Они просто решили, что то, что написано в этих статьях, про distributed file systems и парадигму MapReduce, реализовать, как open-source проект на Java. Началось это еще в 2004 году, когда люди захотели написать открытую поисковую систему Nutch, после этого, где-то в 2005 году, из нее Apache Hadoop выделился как отдельный проект, как реализация distributed file system и парадигмы MapReduce. Сначала это был небольшой проект, не очень стабильный, где-то в 2006 году компания Yahoo начала пробовать использовать Hadoop в своих проектах, и в 2008-2009, компания Yahoo запустила свой поиск, вернее не поиск, а индексацию, которая была полностью устроена на платформе Apache Hadoop, и сейчас Yahoo индексирует интернет, используя платформу Apache Hadoop. Индекс хранится в distributed file system, а само построение индекса сделано как серия Map-Reduce задач. Да, опять же Hadoop недавно выиграл соревнование по сортировке данных, есть такой «1TB sort contest», когда какие-то люди собираются и пытаются быстрее отсортировать один терабайт данных. Регулярно выигрывает система, построенная на основе Apache Hadoop, которая запускается на кластере Yahoo. Mодули Hadoop
Yahoo: web graphЕще вот немного примеров, про то, как допустим, Yahoo, использует Hadoop. Yahoo нужно, например, строить граф всего интернета. В качестве вершин у нас будут странички, если с одной страницы будет ссылка на другую, это будет ребро в графе, и помечено это ребро текстом ссылки. Например, как это делает Yahoo. Это тоже из серии Map-Reduce задач. Сначала Yahoo скачивает все страницы, которые им интересно индексировать, и хранит их, опять таки, в HDFSе. Чтобы построить такой граф, запускается map-reduce задача. Итак, Map, мы просто берем страницу, и смотрим, куда она ссылается, и просто выдает такое вот в качестве ключа, Target URL, т.е. куда ссылается с страница, значение → SourceURL, т.е. куда мы ссылаемся и текст ссылки. Reduce просто получает все эти пары, … т.е. он получает ключ, это TargetURL и набор значений, т.е. набор SourceURL-ев и текстов, делает какую-то фильтрацию, ибо у нас очевидно есть какие-то спамные ссылки, которых мы не хотим индексировать, и возвращает все это в виде таблицы — TargetURL, SourceURL и текст. Такая таблица это граф всего интернета.  Last.fm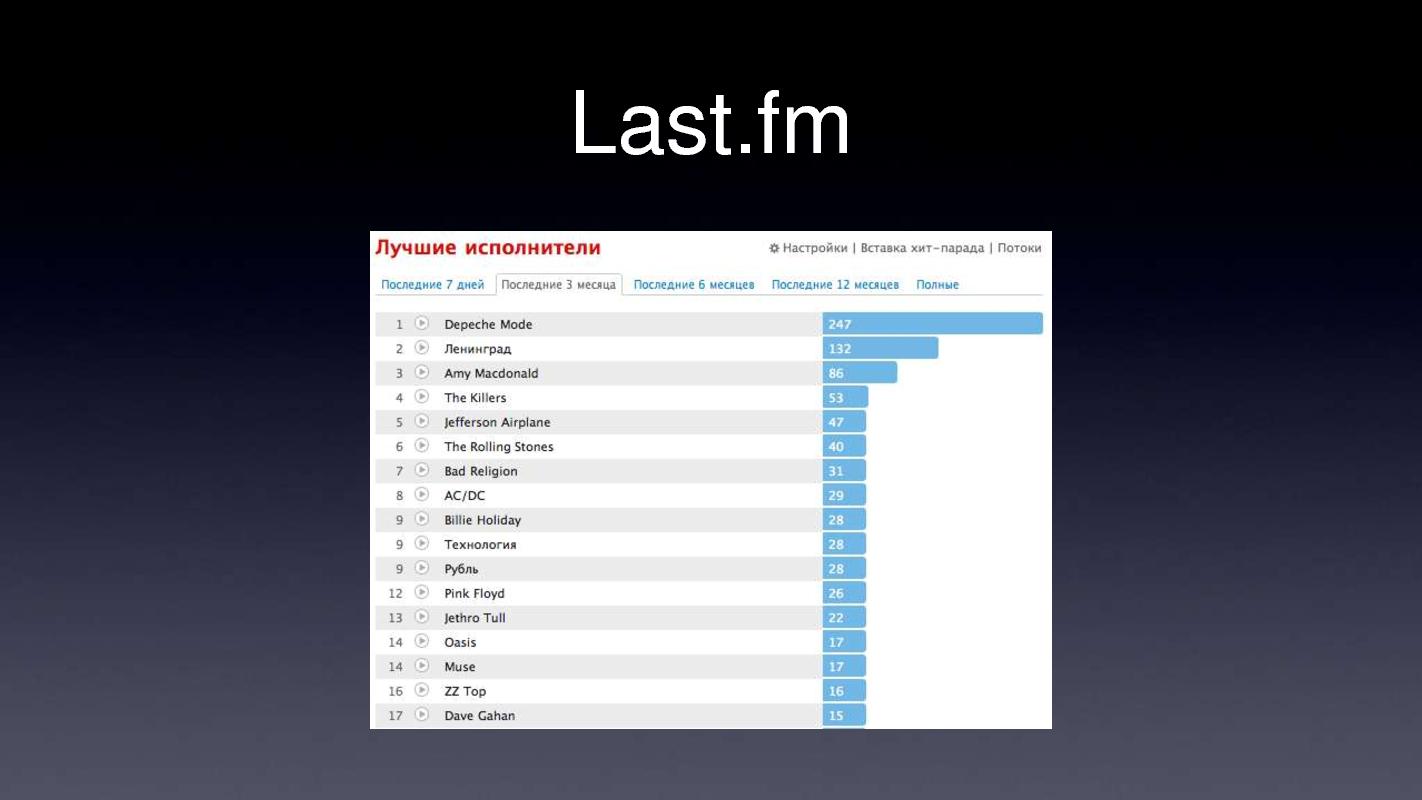 Пользователь слушает песню. Информация о прослушивании записывается в
{userId, band, track} ⇒ (user_band, 1)
(user_band, [1, ... , 1]) ⇒ (user_band, sum)
Опять же Last.fm, наверное многие пользуются, кто не пользуется — немного объясню. Это такой сервис, вы ставите плагин к вашему iTunes-у или WinAmp-у, он посылает на last.fm в реальном времени то, что вы слушаете, после этого Last.fm делает две вещи — например, он строит такие красивые chart-ы, т.е. за последние семь дней или три месяца, какие группы вы слушали, какие у вас композиции, и еще делает какие-то last.fm ??? радио на основе статистики прослушанных вами композиций, они вам рекомендуют что-то другое, что-то новое и интересное для вас, то, что якобы будет вам интересно. Если кто-то заметил, то эти chart-ы, они обновляются не в real-time, раз в день, что-ли, не помню, в общем, нечасто. Собственно эти chart-ы, они строятся снова, на платформе Apache Hadoop. Когда вы слушаете какую-то композицию, просто записывается строчка в лог-файл, «юзер с таким-то идентификатором прослушивал такую-то композицию такой-то группы». После этого раз в день запускается Map-Reduce задача. Как она выглядит?
После этого, когда вы заходите на свою страницу, этот файл парсится, там находится относящаяся к вам запись, и рисуется вот такой чарт, который был на прошлом слайде.
SQLSELECT f1, f2, SUM(a) WHERE expr GROUP BY f1, f2
line ⇒ ({f1, f2}, a) if expr
({f1, f2}, [a1, ..., an]) ⇒ ({f1, f2}, sum)
На самом деле, большое количество SQL-запросов легко параллелится в виде…, легко можно выразить в виде Map-Reduce задач. Например, стандартный SQL, многие пишут, многие таким пользуются, — набор полей, f1, f2, сумма, where, какое-нибудь условие и group by. Т.е. это стандартный SQL-запрос, который используется много где, для построения отчетов и какой-то статистики. Так вот, такой запрос легко параллелится в качестве map-reduce. Вместо таблицы, допустим, у нас текстовый файл, в качестве хранения данных. Вместо SQLдвижка у нас map-reduce. Вместо результатов запросов у нас текстовый файл. Собственно говоря, как это устроено. Map-процесс. В качестве inputа у нас строчки в лог-файле, в качестве output-а, мы эту строчку парсим и выдаем в качестве ключа, поля, которые нас интересуют в качестве group by, и качестве значения, поле, которое мы агрегируем, в данном случае мы считаем сумму a. Reduce получает собственно в качестве ключа эти поля, в качестве значений, набор полей, которые мы агрегируем, т.е. какие-то , и просто делает суммирование. Собственно говоря и все, мы задали такие map-reduce процедуры на кластере и получили результаты для этого запроса. SQL: Принцип
На самом деле множество SQL-запросов можно распараллелить… , можно выразить в терминах map-reduce job. Если у нас есть GROUP BY, поля, по которому мы делаем GROUP BY мы определяем как ключ в процессе Map. WHERE — это просто фильтрация в процессе Map-а. Опять же все суммы, AVG, и прочие агрегирующие функции мы считаем на этапе Reduce. Очень легко реализуется условие HAVING, JOIN и прочее.
SQL: partitioning
Немного про Partitioning. Когда мы так обрабатываем данные, допустим, вот в том же last.fm, мы строим эту статистику, у нас данные хранятся в файле, если мы будем каждый раз запускать map-reduce job-ы на всех файлах, которые есть, это будет очень долго и неправильно. Обычно для данных используется partitioning, например, по дате. Т.е. мы храним все не в одном едином лог-файле, а разбиваем его по часам или по дням. Тогда, когда мы map-аем наш SQL-запрос на MapReduce-job-ы, мы сначала ограничиваем набор входных данных как…, собственно говоря, по файлам. Допустим, если нас интересуют данные за последний день мы берем данные только за последний день, и только потом запускаем map-reduce-jobы.
Apache HiveФреймворк на базе Apache Hadoop
Собственно говоря, этот принцип реализован в проекте Apache Hive, это такой фреймворк, построенный на базе Hadoop. Как все это выглядит с точки зрения пользователя? Мы задаем некоторый SQL-запрос, определяем, где у нас лежат данные, после этого, этот фреймворк выражает этот SQL-запрос в виде map-reduce задач, в виде одной или целой последовательности, запускает их… , для пользователя все выглядит довольно прозрачно. Т.е. мы определили набор входных данных, задали SQL-запрос, и на выходе получили тоже, какую-то таблицу.
Apache PigВторой фреймворк, это Apache Pig, это тоже самое, примерно, решает ту же задачу, т.е. прозрачное для пользователя создание map-reduce job-ов, без того, чтобы писать какой-нибудь код. Мы задаем в таком вот ETL-языке, последовательность, что мы хотим, откуда мы хотим что-то загрузить, как мы будем эти данные фильтровать, какие колонки нас интересуют, и все это транслируется в map-reduce job-ы.  Области применения
Собственно говоря, области применения, всего этого Hadoop-а и прочего. Hadoop очень хорошо применяется для построения статистических моделей, и вообще для анализа данных. Если у нас есть много лог-файлов, мы хотим найти какие-то корреляции, как ведет себя пользователь, в зависимости от чего, такие задачи очень хорошо решаются с помощью Hadoopа, соответственно построение отчетов, опять же, тот же Last.fm. Когда у нас есть много данных, и мы должны строить какие-то отчеты, они нам не нужны real-time, мы готовы их обновлять раз в день, или в несколько часов, тоже все очень удобно.
Достоинства
Достоинства этого подхода, этой платформы. Очень хорошая и гладкая масштабируемость. Т.е. если нам нужно обработать в два раза больше данных, или хранить в два раза больше данных, нам достаточно добавить в два раза больше машин в кластер. Т.е. не совсем ровно в два раза, но почти в два раза. Нулевая стоимость software. Там у вас много данных, вы можете пойти в компанию Oracle, купить за пару миллионов долларов кластерный Oracle, и столько же консультантов, это не всем компаниям подходит, особенно startup-ам. Не знаю, ну какая-нибудь новая социальная сеть, они просто не могут себе позволить потратить несколько миллионов на Oracle. Они могут себе позволить Hadoop, взять кластер и использовать open-sourc-ный Hadoop, как систему анализа и хранения данных. Еще Hadoop удобен для research-задач. Например, вы researcher, и вы хотите исследовать корреляцию поведения пользователей с чем-нибудь на фейсбуке, где-нибудь еще в вашей социальной сети, у вас есть много файлов, hadoop доступен, как on-demand сервис на Амазоне. Т.е. вы написали что-то у себя, локально отладили, говорите, ОК, теперь мне нужен кластер из ста машин на два часа, вам сразу Амазон представляет кластер из ста машин, вы запускаете там свою задачу, получаете какие-то результаты, и все как бы. Сто машин на час у Амазона стоят относительно дешево, дешевле чем у себя хранить кластер. Для research-а это достаточно удобно, то, в том смысле, что вам все это нужно раз в неделю, не нужно хранить у себя кластер, можно заказывать его у Amazon-а.
На час… ну это порядка сотен долларов. Я, често говоря, уже у амазона цену не помню, но это довольно дешево, это вполне доступно.
Да, но для Hadoop-а нужны побольше инстансы, и возможно побольше кластер, ну в общем да, сотни долларов. Это такой порядок, понятно, что если большая задача, то это не час, а десять часов, но все равно, речь идет о сотнях долларов, т.е. о чем-то не очень большом. Недостатки
Во-первых, это довольно высокая стоимость поддержки. Если у вас есть Hadoop-кластер, из многих машин, вам нужно найти умного системного администратора, который разберется в архитектуре Hadoop-а, в том, как это работает, и будет все это поддерживать. Т.е. это действительно непросто, это действительно занимает много времени. Это в отличие от каких-нибудь промышленных и дорогих хранилищ, стоимость новых процессов обработки данных достаточно высокая. Т.е. если вы покупаете какой-нибудь Oracle, или что-то подобное в этом стиле, вам в принципе достаточно, нанять каких-то бизнес-аналитиков, которые будут писать просто SQL-запросы и получать какие-то результаты. В данном случае, такое не получится с Hadoopом, вам нужны будут люди, которые будут придумывать бизнес-часть, какие именно данные им нужны, и вам будет нужна команда Java-разработчиков, которые будут писать эти map-reduce job-ы. Команда не очень большая, но тем не менее, все равно это стоит денег, разработчики довольно дорогие. И опять же, проблема с real-time-ом. Hadoop это не real-time система. Если вы хотите получать какие-то данные, у вас не получится так, что вы будете запускать map-reduce job-ы, когда пользователь заходит на сайт. Вам нужно обновлять данные, хоть раз час, в background-е, а пользователю показывать уже рассчитанные данные.
Real-Time?
С real-timом проблема относительно решаемая. Например, как это решается у нас в компании. Нам не нужно предоставлять real-time доступ, ко всему объему данных, что у нас есть, мы запускаем map-reduce job-ы, получаем какие-то результаты, довольно ценные, но разумного размера, которых мы храним в SQL-базе данных, в MemCache, в памяти, это тем не менее, не будет работать, когда этих данных будет у вас много. Поэтому сейчас … время еще осталось? Осталось десять минут, поэтому я расскажу о column-oriented базах данных, тоже подход к хранению большого объема данных, к которым нужен realtime доступ. Column oriented databases
Другие проблемы с SQL-ем, если вы меняете схему, допустим, какой-нибудь ALTER TABLE, долго и проблематично на большой таблице добавить какие-нибудь колонки. Это довольно проблематично, и когда вам этого не нужно, когда вам не нужно хранить структурированные данные, когда вы снимаете ограничения... не пользуетесь возможностями SQL, как хранилища структурированных данных, не используете реляционность, можете хранить данные в немного более эффективной структуре, и за это получать большую производительность. Это как раз немного другой подход, который называется column-oriented database. BigTable
Удобнее представлять хранилище не как таблицу, а как соответствие: (row key, column name) ⇒ value Так же во многих реализациях данные имеют версионность по времени (row key, column name, timestamp) ⇒ value
Он был представлен компанией Гугл, и до сих пор они его используют, если мне не изменяет память, это статья «BigTable», которая была опубликована в 2004 году. Собственно говоря, что такое BigTable? Он построен на нескольких принципах. Первый принцип, что мы отказываемся от реляционности, от индексации по полям, в нашей таблице есть ровно одно поле, по которому можно производить поиск, то, что называется rowkey, аналог — это primary key в таблице. Все остальные поля мы не индексируем, не ищем по ним, их не структурируем и второй принцип — то, что таблица широкая, т.е. мы можем добавлять колонки в любой момент, с любыми типами данных, должно быть дешево и хорошо.
BigTable: примерЗадача: хранить информацию о посетителях сайта
посещений, история показа рекламных объявлений.
Давайте, я приведу пример, когда это используется. Мы хотим хранить данные о пользователях нашего сайта. Зашел на сайт, сделал какие-то действия, в случае Гугл — сделал какие-то запросы, что-то посмотрел, посмотрел какие-то рекламные объявления, это анонимный пользователь … и мы хотим помнить про то, что он сделал. Как решается эта задача? Многие люди, хранят информацию о пользователях в Cookies, что он сделал, какие страницы посмотрел, какие рекламные объявления посмотрел, на что кликнул. С этим подходом есть большая проблема — размер cookie сильно ограничен, туда нельзя, допустим, записать, историю действий пользователя за последний месяц, не получится, нет места. Как эту проблему можно решить с помощью BigTable? Если у нас есть такое хранилище, как BigTable, мы можем хранить в cookie единственный параметр — уникальный идентификатор пользователя. В BigTable мы будем хранить UserUID, как основной ключ в таблице, и много-много полей, которые нас интересуют, например, история посещений, клики на рекламу, клики на ссылки, и прочее. Чем это хорошо? Тем, что нам заведомо не надо искать ничего по остальным полям. Если мы хотим знать какую-то информацию о юзере, чтобы показать ему соответствующую рекламу, нам нужно искать только информацию по UserID. И также хорошо, что поскольку бизнес может менятся, мы можем добавлять много разных полей, и это будет дешево и хорошо. Собственно для этого очень хорошо использовать BigTable, userID, как rowkey, и все остальные данные, как таблица. BigTable: дизайнRow keys сортируются, данные храняться на кластере
Как это все работает? Такой подход, как у BigTable, он очень хорошо масштабируется на большое количество компьютеров. Т.е. если у нас rowkey, и мы ищем исключительно по rowkey, например, по юзер айди, как я привел в предыдущем примере, то мы можем все данные отсортировать по этому юзерайди, и хранить разные rang-и этих данных на разных серверах. Т.е. как будет происходить запрос «получить всю информацию по данному юзер-айди»? На мастер-ноде хранится информация, какие range-ы хранятся на каких серверах, мы сначала справшиваем, у мастер-ноды, где хранятся интересующие нас данные, затем обращаемся напрямую к этой ноде, и читаем оттуда данные. Опять же очень хорошо — в два раза больше данных → купили в два раза больше машин, немного переструктурировали хранилище, причем не мы переструктурировали, а система, которая преставляет нам доступ, и все, мы можем хранить в два раза больше данных.
HBaseПостроен на платформe Apache Hadoop
• Reduce процесс выполняется на соответствующем region server — происходит исключительно локальная запись данных Эту парадигму BigTable, развивающийся в рамках Apache Hadoo, реализует проект, называющийся HBase. Данные хранятся в Hadoop Distributed File System, которую мы уже обсудили, все прозрачно интегрируется с Hadoop-ом, если мы пишем, какие-то map-reduce jobы, которые возвращают какие-то результаты, есть очень прозрачная интеграция, т.е. результаты Reduce можно писать напрямую в базу данных. Поскольку Reduce операция распределенная, данные опять таки будут писать в распределенную базу данных, в HBase, и в принципе, в сочетании с Hadoopом, все получается очень удобно.
HBase: производительность7 server cluster (16Gb RAM, 8x core CPU, 10K RPM HD)
Например, пример производительности. Вот, довольно простой кластер из семи нодов, нода — это 16 или 8 гигабайт оперативной памяти, довольно простой диск, 10К RPM, несколько ядер на каком-нибудь обычном Intel Xeon, вот тут написаны точные данные. Таблица из трех миллиардов записей, это довольно много, каждая запись это 3-5 полей… И если запустить тест на 300 запросов в секунду на запись и на чтение, чтение будет занимать где-то 18 миллисекунд, запись —— быстрее, где-то 10 миллисекунд. Такой производительности на каком-нибудь MySQLе добится невозможно. С HBase это получается. HBase: недостаткиОколо 1% процента запросов работают сильно больше среднего (порядка 300ms)
Какие недостатки у HBase, и вообще, у этого BigTable подхода? Неструктурированность, т.е. нереляционность. У нас есть только одно индексное поле, по которому мы можем искать, у нас нет join-ов, у нас нет сложных запросов WHERE, ну да, это действительно большие недостатки, но тем не менее, в большой классе задач это просто не нужно. И недостатки не всего подхода, а конкретно HBase, это нестабильный продукт, предпоследняя версия стабильно работает, стабильно работает медленно и довольно неправильно, последняя версия написана хорошо, и работает быстро, но иногда падает, иногда теряются данные.
Hadoop: области использования
И еще немножко про области использования, собственно говоря, map-reduce мы обсудили, это research, это анализ данных, это построение статистических моделей, собственно говоря HBase и BigTable… , да, забыл сказать про один недостаток HBase-а, хотя запросы в целом, довольно быстрые, иногда случается, что какой-то запрос занимает очень много, допустим секунду, нет, секунда это врядли, ну, скажем, полсекунды, триста миллисекунд. HBase можно использовать в таких задачах, когда нам не нужно гарантированное время ответа, когда нам не критична потеря данных, опять же вот, хранение информации о уникальных пользователях. К нам пришел пользователь на сайт, если мы не смогли его идентифицировать, не знаю .… выключился... (выключился микрофон). ВопросыГде не стоит использовать Hadoop
Вы можете еще раз сказать, как работает запрос MapReduce для выборки фейсбука, когда вы запрос приводили. Я просто ничего не понимаю в функциональном программировании, вы сказали … я не понял… в чем идея состоит?
Идея чего? Идея вообще этого MapReduce? Идея состоит в том, что это довольно большой класс задач обработки данных, можно выразить … Вот у нас есть куча файлов, распределенная на тысяче машин, вот. Это логи. Тут у нас есть запрос, «скажи, какие броузеры используют чаще», как он ищет вот?
Ну в смысле, как ищет? Вы задали эти два процесса, map и reduce, и после этого, процесс map-а … Что в map-е задается?
В Map-е функция, просто функция, которая получает на вход строчку, а на выход — ключ и значение. Просто задается такая функция… А что такое ключ и значение?…
можно я отвечу?
Просто термин, даже сам термин …
Как ключ и значение? Просто пара двух строк, условно говоря. Вопрос наверное в данном конкретно случае, что будет ключем, а что — значением?
В случае подсчета статистики? Ключ — это броузер, как я сказал, значение, это единица. Как в логе прописывалось — броузер там, две точки…
Совершенно неважно, что будет ключем, что значением, … Более того, функция map может не существовать, .??? функция. Например, у тебя вся строчка лога может быть ключем, а значение — единицей. … (невнятный спор в зале)
На самом деле, что будет являтся ключем, а что — значением, довольно важно, ибо дальше будет происходить группировка перед процессов reduce. Группировка обязательна?
Обязательна! Собственно поэтому он и является ключем! По ключу будет происходить группировка. Reduce получит ключ, и набор значений, ассоциированных с этим ключем. OK, тогда ключем обязан быть броузер…
Да. … из точки лога, значение для оптимизации осмысленно выкинуть, сделать пустую строку?
Ну, собственно говоря, это и есть, значение какой-то константы, т.е. единица. что значит единичка?
Единичка — это число. Ключ — броузер, а единица — это число. …42, ага. Важнее всего здесь этап reduce, который из шматка данных, из громадного шматка данных, сделает маленький набор, махонькую статистику.
Да, именно. Map-reduce это распределенная SQL ??? … ?
Ну это конечно не совсем SQL, я рассказал о том, как он используется в виде SQL, поскольку это самый простой пример, на самом деле, с помощью MapReduce можно решать намного более сложные задачи. Например, мы, с помощью Map-Reduce, строим статистическую модель по кликам на контекстную рекламу, которая позволяет искать вероятность, конкретного клика на конкретном объявлении. Еще вопросы? Просто уточнить хотел насчет параллельности. Просто суть в том, что у тебя есть огромный лог, и ты его делишь на тысячу серверов, допустим. Делишь лог на тысячу частей, и каждую часть отправляешь…
Да, это опять же делаю не я, это делает Apache Hadoop, т.е. для программиста это выглядит довольно прозрачно. Я просто даю эти функции, и дальше там внутри как-то делится, на каждом кусочке запускается отдельный процесс, который называется mapper, который выполняет map. Потом, все группируется, начинается этап reduce, для программиста там все прозрачно, не нужно определять, как мы там делим файлы. А Hadoop стабильно работает?
Ну, … смех в зале
На самом деле, да, это сложная система, но с хорошим системным администратором она работает стабильно. Т.е. в принципе никаких проблем нет. Опять же Hadoop, несмотря на то, что это сложная система, если у вас какой-нибудь маппер упал, или потерялся connection к node, ничего страшного, вы перезапустите на другой ноде, с теми же там... и в целом, сам дизайн, он довольно стабильный, но вот с конкретно реализацией Hadoop, есть небольшие проблемы. Какие нетривиальные алгоритмы можно использовать? Я имею в виду не просто подсчет «сколько раз встречается», а что-нибудь интересное может быть?
Ну вот как я сказал — мы строим вероятностную модель, которая позволяет предсказывать вероятность клика на контекстной рекламе. Если вам интересна эта конкретная модель… Мне интересно, чтобы можно было сказать «вот это вот такой известный алгоритм»…
Ну не знаю… Мы используем концепцию decision tree, по алгоримту IT Tree, не знаю, если это вам что-то говорит… Мне то говорит, но вопрос то, как именно использовать то…
Ну это очень долгий рассказ, как это использовать, в Hadoop, не знаю, могу после рассказать. А какие еще вещи? ??? … делать эффективно?
Можно. Большой пласт задач решается, мне сложно прямо перечислить их все. А что не решается?
Допустим, если вам нужно, какой-нибудь отчет показывать, если вам нужно строить такое дерево или показывать результаты пользователей realtime, когда нажимают какую-нибудь кнопочку на сайте, то у вас это не получится, поскольку такая джоба у вас может занимать минуту, десять секунд… Ну не знаю, матрица на вектор умножаетяся?
Матрица… Сложный вопрос. Надо подумать. Возможно нет, даже скорее нет. Математические вычисления тоже наверное не очень.
Смотря какие. Некоторые математические вычисления очень хорошо выражаются и параллелятся на map reduce. Некоторые нет. Но в целом, это не какая-то серебрянная пуля, что вот, мы поставили Hadoop и мы можем сделать все, что угодно, наконец-то будет счастье. Нет, это всего лишь один из способов обработки данных, который для каких-то задач оказывается очень удобным. Есть ли большие компании, которые пользуются Hadoopом?
Я, например, использую Hadoop для построения поиска, для построения поискового индекса. Компания Facebook использует Hadoop для research and development, они записывают действия пользователей в лог-файлы, которые хранятся на distributed file system, их research developers пишут какие-то map-reduce jobs, какие-то расчеты пишут, какие-то корреляции ищут, изучают какие-то статистические модели. На самом деле много компаний его используют, вот, например, Yahoo, Facebook — наверное самые крупные. А про Hadoop++ расскажите пожалуйста.
А я даже не знаю, что это такое. А Yahoo, то получается уже не использует, у них поисковик сейчас Bing-овский стоит.
Да, сейчас они вообще закрывают этот бизнес, переходят на Bing-овский поисковик. Но тем не менее, сейчас поисковик работает, он работал два год на Hadoopе, и в общем-то, поиск был такой, что у них работало. Почему Гугл тогда это в своем поиске не использует?
Гугл использовал map-reduce и distributed file systems для построения и хранения индекса, до недавнего момента. Где-то месяц назад они аннонсировали, что их новая система поиска и построения индекса не использует map reduce, использует что-то новое. BigTable они используют…
BigTable она использует для собственно говоря хранения индекса, чтобы был real-time доступ, это всегда использовалось. Тем не менее, именно для обработки данных, для того, чтобы по большому объему страниц построить индекс, построить собственно говоря BigTable, в котором хранятся данные, раньше использовался map reduce, сейчас используется что-то новое. А вы используется такие объемы данных для чего?
В нашем случае, мы компания, которая показывает контекстную рекламу, мы генерируем по 115 гигабайтов файлов в день, мы хотим получать какую-то ценную информацию из этих лог-файлов. Минимум, это какие-то репорты для аналитиков, для собственно говоря, наших клиентов, рекламу которых мы показываем, и также для построения статистических моделей, которые позволяют нам принять решение, какую рекламу показать какому конкретному пользователю, чтобы он с большей вероятностью кликнул, например, или там… Вот у меня есть вопрос — предположим, я ненавижу open-source, люблю Microsoft, терпеть не могу хиппи и Apache Foundation, например. Что мне делать вместо Hadoop-а, например?
Например, что вместо Hadoopа делать, тащем-то? Есть какая-то реализация, тоже опенсорсная, на сишарпе, которая используется в MySpace… Не-не-не… У микрософта ведь есть Windows Azure, это ведь что-то такое ……
Нет, Windows Azure это что-то другое, это ведь аналог Amazon EC2, там можно покупать машины… Нет, там у них есть хранилище, хранилище огромное… у амазон такого нет, а там есть мап-редьюс, только от микрософта?
Нет, насколько я знаю, нет. Если они конечно выпустят какой-нибудь map-reduce, он будет стабильней, чем hadoop. Есть какие-нибудь вещи, похожие на map-reduce, но рилтаймовые?
Что значит похожие? Подход map-reduce, это обработка большого объема данных на кластере, так чтобы... Вот да, подходящие для обработки такого же объема задач, но рилтаймовые.
Ну вот BigTable, опять таки. Вы обработали данных, храните их в BigTable, в HBase, как я описал. … но ведь не обрабатывает…
Вы хотите все сразу — и обработать данные и куда-то их сохранить, и все это real-time. ну может есть класс задач, которых можно решать рилтайм…
Ну если вам нужен рил-тайм, храните данные в бигтейбле, быстро к ним доступайтесь, что-то быстро в памяти считайте, но такого нету. А у меня есть маленькое количество данных… чтобы работать быстро…
Если у вас маленькое количество данных, то используйте обычный SQL и не выпендривайтесь. Расскажите чего-нибудь про Pig.
Про Pig? Я уже сказал, что это фреймворк поверх Apache Hadoop, вместо того, чтобы писать конкретные мапперы и reduce, вот у меня был слайд с примером кода, А к этому всему SDK какой-то есть?
Вот пример кода, Мы пишем в таком виде, в декларативном виде, какие данные нам нужны, и этот запрос будет распараллелен на map-reduce. Там интерпретатор, что-ли есть?
Ну там есть интерпретатор, он строит синтаксическое дерево, потом анализатор этого синтаксического дерева, который понимает, какие какая процедура мапа, какой редьюс, ведь это скорее не один мап-редьюс, это будет скорее sequence мап-редьюс задач, и все это запускает. А мап-редьс на Java пишется?
Ну нативное API на Java, потому что сам Hadoop написан на Java. А есть SDK под другие языки?
Есть SDK, есть. Есть такое понятие streaming, это что-то вроде CGI, когда вы пишете скрипты, которые получают тексты и выдают тексты, и писать вы их можете на чем угодно. Есть более продвинутое API для С++, COM, для Python-а. Вообще можно писать на чем угодно, на Java быстрее всего, поскольку API нативный. Аналог ODBC есть какой-нибудь?
Нету, нету. Про Pig я слышал, что люди написали простой скрипт на Pigе, потом переписали его на Map Reduce и он заработал у них в десять раз быстрее. Что нибудь изменилось в этом плане, стал он эффективнее?
Мы изучали… , у нас есть свой фреймворк, in-house, который описывать flow XML-ей, из которого потом снова генерируются map-reduce jobы. Мы пытались перейти на Hive, на Pig. С Hive ничего не получилось, с Pig-ом, … уже не я занимаюсь этим проектом, в принципе вроде получается, и довольно быстро. Там, где нет XML-я, нет Enterprise. А у вас большая компания.
У нас средняя компания. А Pig выполняет … оптимизации.
Конечно выполняет, что-то он пытается делать. Я не могу сказать, насколько хорошо он это делает, сформулировать класс задач, которых он оптимизирует. Тем не менее, для простых задач он делает, настолько же быстро, как нативный код на Java. В целом, в принципе, много чего оптимизирует. Примечания
Репликация: База Знаний «Заказных Информ Систем» → «Apache Hadoop (Владимир Климонтович на ADD-2010)» Любые правки этой статьи будут перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion». |
|
