В задачах масштабирования можно выделить несколько типов нагруженных систем. Один из них, про которые многие наслышаны, это масштабирование сайтов c огромным количеством пользователей (Google, Facebook, Amazon, eBay).
Михаил расскажет о менее известном — масштабирование различных систем планирования и управления заказами и прогнозами продаж — на примере решения, которое было разработано для одного из крупных ритейлеров США.
Будут кратко описаны:
Предметная область — что вообще такое Supply Chain Management и зачем он кому-то нужен (в каких отраслях используется, какими компаниями, с какими проблемами сталкиваются разработчики этих систем)
Основные компоненты SCM-системы для розничной торговли — хранилище данных, интеграция с инфраструктурой клиента, модуль анализа поступающих данных, интерфейс пользователя
И подробно рассмотрены вопросы:
Специфика масштабирования SCM-системы для ритейла «вообще»:
Пользователей мало — данных для анализа много
Интеграция с узлами Supply Chain
Откуда возникают ресурсоемкость и временные ограничения на обработку
Особенности пользовательского интерфейса
Какой стек технологий мы использовали и почему
Собственно масштабирование
Как хранить большие таблицы (>5 млрд записей) и индексы
Как быстро и надежно загружать ежедневно приходящие данные
Как параллельно обрабатывать большие объемы клиентских данных
Отзывчивовость интерфейса, работающего с большими объемами данных
Мониторинг производительности, принципы и инструменты.
JProfiler, Explain Plan, Oracle Grig Control. Где же в итоге тратятся ресурсы?
В завершение — в чем сходство и различия по сравнению с масштабированием нагруженных сайтов?
Видео
Видео в HD-качестве, смотрите в полноэкранном режиме.
В общем и целом, я считаю, что выступил неплохо. Да-да, дальше идет абзац хвастовства, можете его пропустить, если вам такое не по нутру, а я отведу душу.
Что было? Было внимание ко мне и тому, что я говорил, со стороны присутствующих в зале, не было (кажется :)) людей, сидящих в первом ряду и втыкающих в нетбуки, айфоны и айпэды, было немало вроде бы искренне-заинтересованных вопросов после моего доклада. Было обсуждение на час-полтора в коридоре после выступления, на котором мы обсудили кучу интереснейших, но уже довольно узкоспециальных вещей (вроде оптимизации тяжелых баз данных на Oracle, бизнеса управления поставками, data mining-a, статистического анализа, бизнес-логики на Groovy и почему это не совсем маразм, и еще кучу всего). В итоге собрали неплохую такую кучку в кулуарах, даже из JetBrains некоторые ребята подтянулись послушать и пообщаться :) Были люди, подходившие ко мне после доклада, хлопавшие по плечу и говорившие — «чувак, ты реально зажег». Были, наконец, какие-то упоминания в паре блогов и в твиттере.
Тем подозрительнее тот факт, что особенной критики в свой я (пока) не слышал. Может, просто не натыкался еще, или критики мой доклад проигнорировали, и писать отзыв им стало лениво (а жаль…). В любой случае, конструктивной критике буду рад.
Сложновато из-за непривычки оказалось выступать в таком зале, говоря в микрофон с выходом на мощные фронтальные колонки. Первые несколько минут меня жутко сбивал с толку собственный голос, доносившийся с некоторым лагом, и я не мог себе представить, как меня слышат (или не слышат вовсе) сидящие в зале. Но потом вроде приноровился.
И тут же небольшое замечание. Я старался держаться на сцене энергичным и бодрым, а не как манакен с вмонтированным устройством для озвучки слайдов, но этому препятствовал в какой-то степени микрофон, который приходилось держать в руке близко к ротовому отверстию. Реально — радиогарнитура, прикручиваемая к голове был бы куда удобнее (с другой стороны, микрофон для многих докладчиков решает извечную проблему — куда же девать руки во время рассказа:))
А так — все было классно. Не считая некоторого волнения — получил искреннее удовольствие от выступления, от ответов на интересные, по существу, вопросы в конце и от общения с аудиторией. Надеюсь, она тоже свою порцию удовольствия получила :)
Особенности масштабирования систем планирования и управления поставками (Михаил Антонов, ADD-2011)
То самое случайное 100 % попадание — компания делает почти то же, что и мы, только круче :) обслуживает крупные западные сети, планирует им поставки с помощью купленных библиотек с алгоритмами. Тоже используют этот дурацкий Oracle, который масштабировать настолько дорого, что проще перейти на MySQL, и кучу Java-серверов приложений, которые как раз добавить дешевле. Собственно, заказчики консервативные и это предпочитают тоже. И объёмы данных у них огромные. И библиотеки прогнозные только под винду.
По описанию доклада это был чисто наш кейс. Так и оказалось. Ребята из Самары автоматизируют процессы для крупных американских продуктовых ритейлеров. Тот же Oracle, те же сервера приложений (правда на Java). Тот же самописный ORM, те же сложные запросы, не укладывающиеся в ORM и написанные на голом SQL. Тот же ExtJS для веб-морды. В общем, мы явно идем в струе.
После оооочень долгого описания предметной области докладчик наконец-то перешел к техническим подробностям. Я сильно не вслушивался, так как в производительности Оракла не копенгаген, но нашим проектам, где Oracle хочется ускорить, может быть получится узнать что-то новое. Хотя, наверняка у нас примерно то же самое все и используется.
Из интересного — сервера приложений у них хоть и на Java, но все равно на Windows 2003 сервер, так как какие-то аналитические библиотеки доступны только как dll.
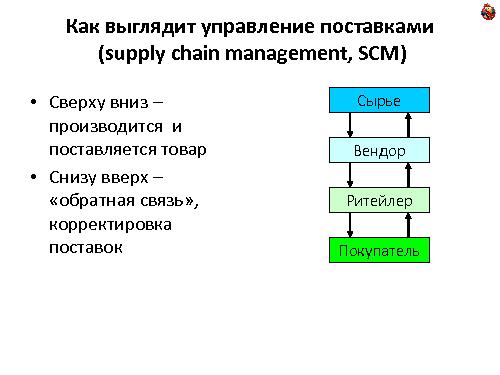
Системы управления поставками для крупных американских и некоторых европейских ритейлеров. Сырье — Вендор — Ритейлер — Покупатель. Товар вперед, по заказам. Без возвратной логистики. Очень интересный для меня доклад, поскольку наша компания, в числе прочего, занимается именно проектами управления снабжением магазинов для Спортмастера.
Сам доклад — очень удачный. Михаилу удалось в кратком докладе рассказать о бизнес-задаче управления цепочкой поставок, о технических сложностях ее решения и о методах оптимизации. Задача, по моему опыту, весьма сложная и то, что они деляют — впечатляет.
Бизнес-задача — снабжение магазинов на основании текущих остатков и прогнозов продаж.
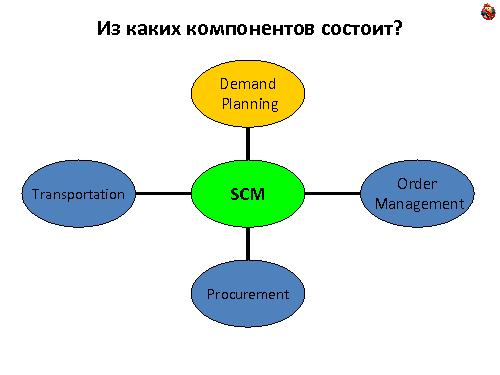
Содержание SCM
demand planing — предсказание объема продаж,
статистический долгосрочный прогноз
эвристический краткосрочный прогноз
order management — реальные заказы, опираясь на прогнозы
transportation — транспортная логистика
исполнение
Прибыль ритейлеров — 1-4 % от оборота даже в успешные годы. Поэтому очень важна точность прогнозов.
Региональные центры дистрибуции, по 2 на штат. Заказ в магазины и пополнение центров дистрибуции. Тысячи магазинов, до 15 тыс. у одного европейского ритейлера
Прогнозирование — data mining. Эвристики, которые дорабатываются по прецедентам в процессе эксплуатации. Оно живет, но неудачи — опасны.
Особенности работы с заказчиком.
Процесс прогноза и заказа идет автоматом, но должны быть механизмы наблюдения, анализа и корректировки.
Процессы у заказчика — медленные. Например, получить одну нужную колонку в данных — 4 месяца.
Консервативность заказчика к технологиям. Поэтому Oracle + Java. Используют Groove для бизнес-логики не афишируя — все равно Java-платформа.
Система обеспечивает решение следующей задачи. Надо ежедневно получать данные о продажах, конвертировать, валидировать, загружать. Далее — обрабатывать, обеспечивая создание заказов и корректируя имеющиеся прогнозы, долгосрочный и краткосрочный. При этом время на обработку ограничено — после получения всех данных и до первой стадии бизнес-процесса обработки заказов, обычно на это 1-1.5 часа. А объемы данных большие, оценка — 2К маг * 50К товаров (продаж в день) * 500 дней = 50 млрд строк продаж. Реально 5-10 млрд.
Пользователей системы мало, десятки-сотни они эксперты в предметной области. И они наблюдают за процессом и тушат пожары. Обнаруживать и тушить надо быстро, для этого им надо быстро и наглядно представить данные.
Система работает для нескольких заказчиков. У них есть общее ядро и дальше — настройка на заказчика. При этом граница системы проходит по-разному, различна и степень вмешательства пользователей — в одних случаях пользователи подтверждают каждый заказ, в других работает почти автомат. Алгоритмы прогнозирования они делают сами, однако существует учебный режим, в котором пользователи формируют статистику для работы алгоритмов или тестируют. Но реальная проверка — все равно на боевых данных.
Технологии.
Oracle 10g/11g RAC
Java 1.6 Jboss AS 4.2. Jboss используется исторически и как общая платформа с другими проектами.
Собственный Cache и grid-manager
Клиент JSP, JavaScript.
Для бизнес-логики используют Groove
Задачии оптимизации
Хранение больших таблиц
Быстрая загрузка
Оптимизация запросов
Оптимизация БД в целом
Оптимизация интерфейса
Оптимизация engines — расчетных частей
Большие таблицы — Partitioning. Если пара таблиц имеет одинаковый partitioning, то join это учитывает.
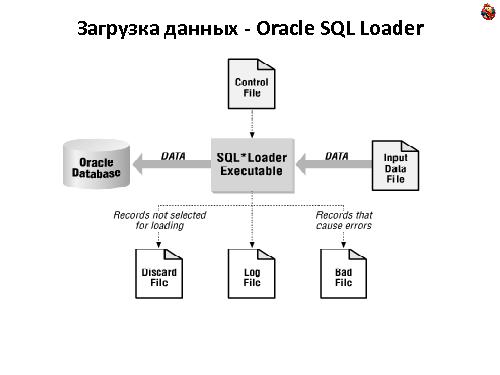
Загрузка — SQL*loader, с использованием различных ускоряющих приемов.
direct mode, отключение индексов, constraint, редкие commit, увеличение буфера
отключение redo-log,
параллельная загрузка по внешних процессов
Загрузка во временную таблицу, потом merge для разрешения ссылок. Разбивают на части.
flat table — монтировать csv-файлы как таблицы
Оптимизация запросов по планам решения. Реально оптимизатор — улучшается. Сейчас они удаляют хинты, написанные 3-4 года назад.
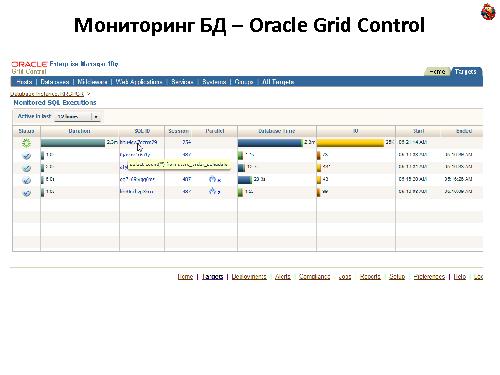
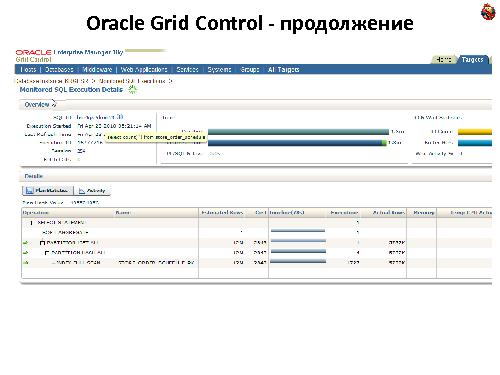
Oracle Grid Control. Вкладки мониторинга запросов — он показывает еще и динамический план: сколько записей в запросе и столько он уже вытащил. И известный способ — трассировка sql_trace, tkprof.
Оптимизация пользовательского интерфейса
materialized view, вынос в них тяжелых частей запроса, обновление по ночам или несколько раз в сутки
обеспечивают отклик 5 сек.
принудительная фильтрация ui как мера предосторожности — например, не показывать средние продажи по всему восточному побережью — запрос уйдет в БД и многим помешает.
Пакетная обработка — цепочка engines. Масштабы впечатляют — 10К одновременных тасков, 2M всего в таблице. И это — наиболее критичная задача.
В каждом engines — параллельно запускаем задачи обработки, для чего выделяем группы данных, обрабатываемых.
Oracle масштабировать дороже, чем Java/JBoss. Поэтому расчет на сервере приложений. 4-6 серверов Java на каждый сервер Oracle.
Проблемы ввода-вывода на уровне базы данных
Трафик между БД и Сервером приложений — меньше, чем проблема ввода-вывода самой БД — на сервер приложений идут агрегированные данные. Задержки по БД-app их не волнуют, потому что параллельно идет много задач, ограничение — целиком
Железо — в datacenter, тестируют, предпочитают стандартное, так как легче масштабируется.
Облака — использовать начинают. Но amazone — использует сервера общего назначения, а они — оптимизированные под БД. Так что пока осторожно.
Пишут запросы вручную, не через ORM.
Используют HP и др. storage device
Используют flash памиять, Увеличивают размер памяти.
В 11 Oracle используют сжатие данных на exologic и др — на storage
Для меня доклад оказался самым интересным на конференции — полное совпадение:
тип заказчика (крупные ритейл),
близкий бизнес-процесс,
похожий стек технологий.
Компания, основной центр разработки которой находится в Тольятти, предоставляет услуги расчета планов поставок в розничные магазины ритейл-сети со складов (Distribution Center или РЦ в принятой у нас терминологии) или напрямую от поставщика.
На вход они получают данные о продаж и остатках в магазинах и складах, на выходе — предписания отвезти товар со склад в магазин.
Алгоритмы они пишут сами (сложную математику закупают в виде библиотек), железо также обеспечивают самостоятельно (арендуют в дата-центрах).
Кстати, очень хвалили специализированные аппаратные решения для Oracle, типа Exadata. Впрочем, сразу была оговорка об их недостатках — если что-то сломалось починить без дорогостоящих и редких специалистов сложно. В конечном итоге, я так понял, большая часть используемого железа — это все-таки конвенциональные сервера.
На вопрос об облачных решениях ответил, что только начинают присматриваться, но уже вполне серьезно рассматривают такую возможность, в частности, Amazon,
Кто их клиенты?
Крупнейшие retail-сети, как европейские, так и американские
Особенность retail-бизнеса в том, что при высоком годовом обороте (до 100 миллиардов долларов в год для крупнейших сетей), чистая прибыль колеблется на уровне 1-4 % процента
Поэтому точность определения спроса очень важна. Увеличение продаж на 1 % дает сотни миллионов долларов дополнительного дохода.
Какая задача системы?
Получать данные о продажах и остатках за определенный период времени (обычно сутки).
Накапливать данные.
Строить краткосрочные прогнозы продаж (эвристики — Data Mining).
Строить долгосрочные планы (математическая статистика).
Создавать заявки на перевозку товара со складов или заказы производителям.
Мониторить продажи и вносить корректировки.
Задача оперативного обеспечения отгрузок и перевозок решается системами клиента.
В случае Спортмастера эта система как раз RMS. Получается, что мы с Magentа не конкурируем — мы не раз говорили о том, что мы, во всяком случае на данном этапе, не занимаемся Data Mining и Buisness Intelligence, а они не занимаются оперативным обеспечение поставок.
На чем сделано?
Крупные компании обычно очень консервативны, поэтому особого богатства выбора быть не может. В результате используются:
Oracle 10g (используется RAC — Real Application Clustering, технология распределения работы с одной БД на несколько физический машин), на Linux
Java 1.6, на Windows Server 2003 (Windows используется из-за того, что многие алгоритмы доступны только в виде нативных Windows dll).
Собственный Cache/Grid Manager
JSP, Struts, JavaScript (Ext.JS) для пользовательский интерфейсов
Flash, также для пользовательских интерфейсов, с недавнего времени.
Что интересно — часть логики сервера приложений начали писать на Groovy.
Собственно, масштабирование
Докладчик выделил несколько типов задач, которые требуют быстрого выполнения, а значит оптимизации и масштабирования. Максимальное время исполнение ограничено циклом бизнес-процесса в retail-сети — для того, чтобы данные дня вчерашнего можно было учитывать в сегодняшних продажах, нужно уложится за 1.5-2 часа (остальное время занимает исполнение заявки системами клиента: корректировка заявок экспертами людьми, подготовка товара на складе, транспортировка до магазина)
Оценка объема данных:
2k магазинов * 50k товаров * 500 дней = 50 * 109 = 50 миллиардов фактов продаж в финансовый год (почему-то длительность взяли в 500 дней).
Загрузка больших объемов данных из внешних систем
Данные присылают ежедневно в виде упакованного csv-файла объемом порядка 10 Гб (сводные данные по сети).
Используется SQL*Loader для загрузки содержимого файла в БД, без дополнительной обработки. Используется, я так понял, режим Direct — прямая запись данных в файловую систему, минуя механизмы БД, что позволяет добиться очень высокой скорости обработки
Перед загрузкой файл режется на части по несколько сот мегабайт, которые загружаются параллельно
Иногда используется фича Oracle под названием External Tables — возможность подключить CSV файл как таблицу и делать к нему запросы. По сути, удобная обертка над SQL*Loader
Хранение данных. Построение запросов к огромным массивам данных
Активно используется партиционирование.
Соответственно, запросы стараются строить так, чтобы затрагивать только одну партицию
Давно пора попробовать в RMS
Настройка и мониторинг в целом
Используется Oracle Grid Control (есть версия для одного сервера — Oracle Server Control). Что он умеет:
Показывать TOP грузящих сервер запросов
Показывать реальный план исполнения
Показывать план в динамике — сколько данных уже зачитано на данный момент.
Другой друг разработчика — tkprof (утилитка для обработки низкоуровненых трейсов БД). Последнее средство понять, что же торомозит или не работает.
Оптимизация работы UI
Идеальная система управления поставками — это система, у которой нет пользователей, полный автомат. Но в жизни идеал недостежим, поэтому пользователи все-таки есть.
Они обычно:
тушат пожар
потребляют большие объемы данных с разным уровнем аггрегации, для которых нужна быстрая и удобная визуализация.
Поэтому все запросы с UI — максимально простые и предвычисленные.
никаких динамически получаемых сложных запросов!
используется materizalized view
агрегация заранее
принудительная фильтрация
Оптимизация механизмов предсказания
Тут все сделано за счет серьезного распараллеливания на сервере приложений. Докладчик сказал, что в Oracle параллелить проще, но слишком дорого — каждый новый instance Оракла стоит несколько десятков тысяч долларов.
Любые правки этой статьи будут перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion».