Аннотация
- Докладчик
- Евгений Кирпичёв
- Соавтор
- Станислав Лагун
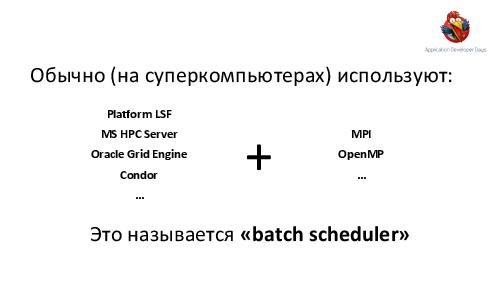
В докладе пойдет речь о том, как разработать инфраструктуру для массивно-параллельных высокопроизводительных вычислений на кластере из многих тысяч ядер с сотнями одновременных задач очень разной и непредсказуемой длительности и степени параллелизма. Будут освещены наиболее интересные аспекты построения такой архитектуры:
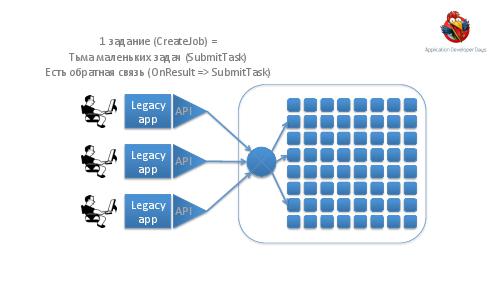
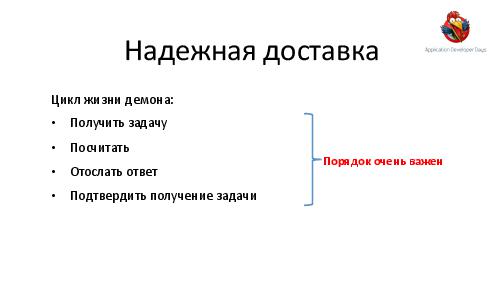
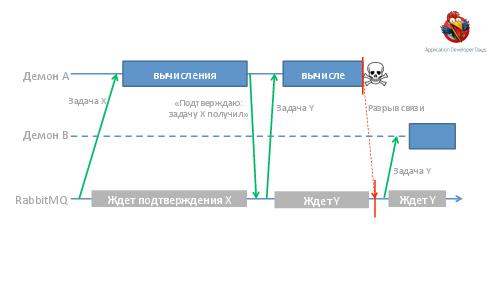
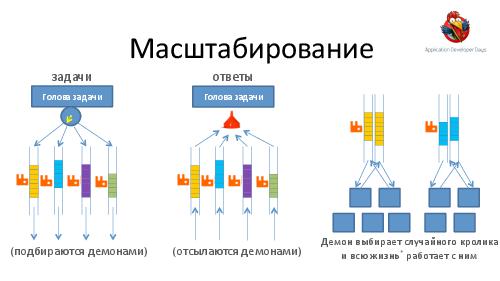
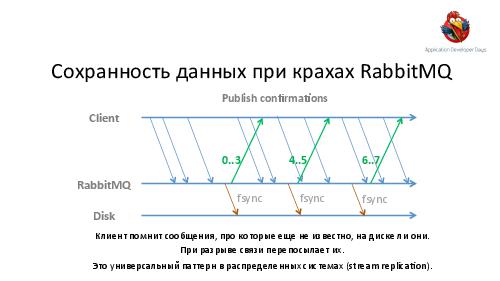
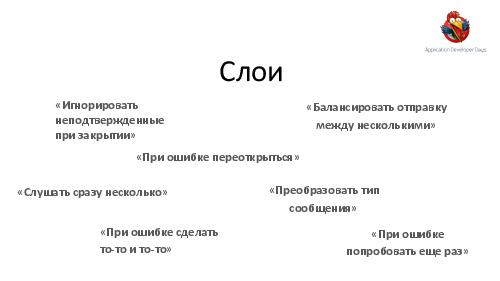
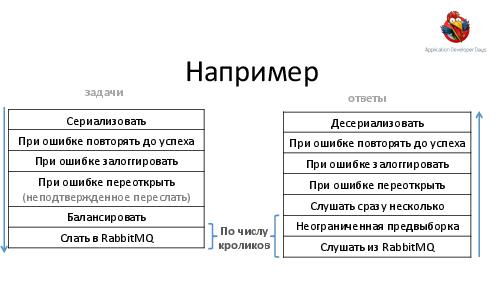
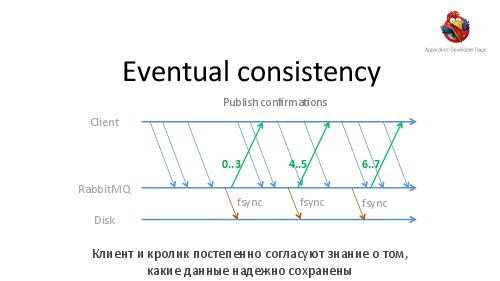
- Достижение высокой надежности и производительности транспорта задач и результатов. Как можно построить такой транспорт поверх RabbitMQ ("из коробки" RabbitMQ, будучи лучшим продуктом в своем классе, все же оказывается весьма далек от требуемых качеств).
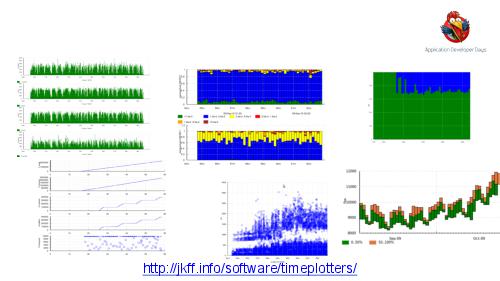
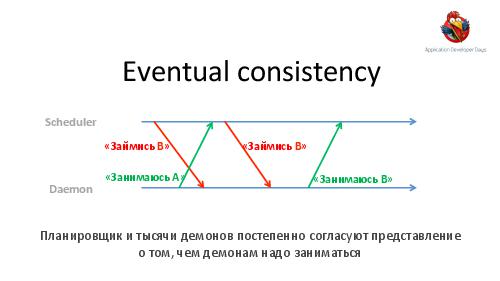
- Отладка и анализ. Понимание поведения подобной большой системы требует специального инструментария. Мы расскажем об очень мощных инструментах логгирования и визуализации, позволяющих в большинстве случаев замечать даже довольно тонкие проблемы с первого взгляда на логи.
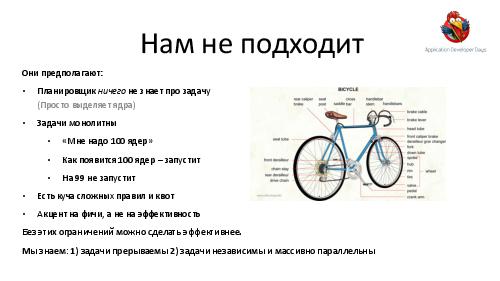
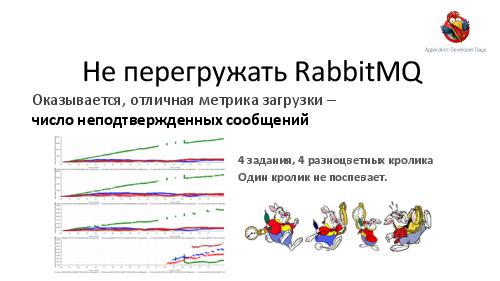
- Под огромными нагрузками многие подсистемы на всех уровнях технологического стека начинают ломаться или вести себя неподобающе в неожиданных (или просто непродуманных) местах; рассказывается, как предвидеть и предотвращать подобные поломки под нагрузкой.
Целевая аудитория
Разработчики больших распределенных систем. Сведения из доклада можно использовать по прямому назначению — для переиспользования описанных решений и ненаступания на описанные грабли в области, например, масштабируемого транспорта задач/результатов; в области отладки; в области capacity planning и предотвращения перегрузки подсистем.
Видео
Видео в HD-качестве, смотрите в полноэкранном режиме.
HTML-код включения <iframe src="http://player.vimeo.com/video/42760159?byline=0&portrait=0" width="800" height="320" frameborder="0"></iframe>
Оцените доклад «Как разработать вычислительную инфраструктуру для большого кластера (Евгений Кирпичев, ADD-2012)»:
Слайды
Примечания и отзывы