Сравнительный анализ хранилищ данных (Олег Царев и Кирилл Коринский на ADD-2010)
Содержание
Аннотация
Известные эксперты по высоким нагрузкам,
- Коринский Кирилл — R&D компании Yota, nginx-хакер, эксперт NoSQL хранилищ, и
- Олег Царев — Software Engineer компании Percona, MySQL хакер, эсперт SQL баз данных.
выступят с большим совместным докладом «Сравнительный анализ хранилищ данных». Существует разные системы для хранения данных: как классические SQL решения, так и модные NoSQL. Поиск серебряной пули вытекает из ограничений реального проекта. Ограничения зависят как от окружения проекта (кадры, бюджет, сроки), так и от формулировки задачи. Мы продемонстрируем связь между ограничениями, структурами, алгоритмами, и реализациями различных хранилищ данных. Когда нужно брать Riak? Чем силён Hadoop? Когда не обойтись без MySQL? А может просто купить Oracle? Любой highload-проект складывается с одними и теми же проблемами.
- Всегда органичен бюджет
- Пользователи имеют свои ожидания
- Вычислительные мощности ограничены
- Сроки ограничены
- Квалификация кадров влияет на все остальные параметры.
Особняком стоят инженерные проблемы — именно они ключевые. Для подавляющего большинства людей эти проблемы являются «чёрной магией». Для менеджеров: Почему существенно увеличив бюджет на железо получили не значительный прирост? Для программистов: В каком хранилище сделано «нормальное» шардирование? Большинство проблем решаются просто:
- Инвесторов можно привлечь
- Целевую аудиторию можно привлечь и удержать.
- Железо можно проапгрейдить
- Сроки передвинуть
- Кадров купить
Инженерные проблемы — это притча во языцах любого массовго проекта. Постоянно, вновь и вновь, находят «серебрянные пули»… Но серебро оказывается сусальным, а то и вовсе медью.
Кирилл Коринский (RooX) и Олег Царев (Percona) — мы не ищем серебрянную пулю. Цель нашего доклада — продемонстрировать, доказать почему её НЕТ. Каждый со своей стороны и одновременно — с одной и той же.
Видео
Презентация

























































Стенограмма
Стенограмму по видеозаписи записал Стас Фомин.
Постановка проблемы
- Постановка проблемы
- Что такое распределенные хранилища
- Обзор доступных хранилищ
 Кирилл Коринский:
Кирилл Коринский:
- Во-первых, почему нет универсального хранилища?
- Почему нет универсального решения, на все случаи жизни?
- Почему хранилища отличаются друг от друга?
Чтобы дать ответ на эти вопросы, нужно понять следующее.
- Чем задачи отличаются друг от друга?
- Почему хранилища сложны?
- Почему невозможно решить все проблемы сразу?
В нашем докладе вы узнаете:
- Почему необходимо распределенное хранилище.
- Каковы основные характеристики хранилищ
- Сравнительный анализ существующих хранилищ
В первой части Олег опишет проблемы, вынуждающие нас использовать распределенные хранилища данных. А я расскажу, какие аспекты распределенных систем важны при выборе хранилища. После этого, мы вместе рассмотрим имеющиеся реализации.
Друзья в социальной сети
Друзья в социальной сети
Задача: получить список друзей.
- 500M пользователей - 5M rps
- ВКонтакте
- 100M пользователей - 1M rps
- Мой Мир
- 50M пользователей - 0.5M rps
- Toy net
- 10 пользователей - <1 rps
 Олег Царев:
Олег Царев:
Для начала давайте рассмотрим несколько популярных социальных сетей. Почему они интересны? Социальные сети имеют весьма жесткие характеристики по нагрузке на них, много пользователей, много показов в секунду, и требуется решить немало проблем, чтобы система работала удовлетворительно, без перебоев.
Собственно, мы выбрали лишь часть из них, это Facebook и их российский аналог ВКонтакте, МойМир, социальная сеть Mail.Ru, и для сравнения, игрушечная сеть на десять пользователей, Toy net, просто как пример.
Матрица смежности — таблица:
- оси таблицы – пользователи;
- ячейки таблицы – связь.
- ВКонтактe/Facebook: один бит
- Мой Мир: шесть байт
- Toy net: один бит
Задача, которую мы будем исследовать, выглядит весьма просто. Нужно ограничить во-первых, пользователей, во-вторых, отношения между ними. Т.е. «кто с кем дружит?».
Данные отношения представляются обычно в виде графов. Граф — это множество вершин, и ребер. Вершины у нас — это пользователи, Петя-Маша-Вася, а ребра — это отношения между ними, вершины соединены ребрами.
Отношения бывают разные. Facebook, ВКонтакте, и наша игрушечная сеть ToyNet — это просто обычная связь, либо дружит, либо нет. А МойМир имеет более сложную структуру, связи детализированы — брат, родственник, дружит, ненавидит, т.е. там весьма сложные отношения возможны. И для хранения простых связей, ВКонтакте, Facebook, ToyNet нам требуется один бит, элементарная единица, а в МойМир требуется шесть байт.
Информацию мы взяли из доклада на Highload, за 2009 год от Mail.ru.
И представляется все это обычно в виде матрицы смежности. Т.е. у нас столбцы и строчки — это пользователи, а их ячейки на пересечении — это отношения.
Список смежных вершин каждый элемент:
- пара (UID, UID), UID — 4 байта:
- Вконтакте
- Toy net
- кортеж (UID, UID, Info — 6 байт):
- Мой Мир
Иным представлением является список смежных вершин. Это просто пара из двух идентификаторов пользователей, организованная в виде списка. Т.е. если у нас в списке есть элемент UserID Пети и UserID Маши, значит между ними есть отношения. Если этой пары в списке нету, значит отношения между ними нет. Ну, в случае МоегоМира нам требуется еще дополнительные шесть байт на описание собственно отношений. Что между Машей и Петей у нас есть — дружба, ненависть, родственные какие-то отношения.
Генерация списка друзей
Каждый элемент:
- Facebook/ВКонтакте - 8 байт.
- Мой Мир - 14 байт.
- Toy net - 1 байт?
Давайте теперь рассмотрим, как для какого-то пользователя, например для Пети, получить список всех его отношений. Суммарный объем связи у нас в Facebook/ВКонтакте это два идентификатора пользователя, так как у пользователя берется четыре байта. Почему мы говорим про байты — это важно, об этом мы поговорим чуть позже.
Тут все очевидно. ToyNet — нам достаточно одного байта.
Матрица смежности:
- Сканируем строку таблицы
- Проверяем каждый столбец строки
- Каждая ячейка сообщает отношения
Так вот, как выглядит генерация списка друзей для матрицы смежности. Напоминаю, это табличка, из столбцов-пользователей и строчек. Мы должны взять строчку из этой таблицы, например для Пети, и пройтись по всем ее ячейкам. Каждая ячейка относится к какому-то пользователю, и сообщает отношение Пети с этим пользователем.
Просто → Список смежных вершин:
- Каждый элемент - (Кто?, С кем?, Что?)
- Фильтруем список по «Кто?»
- Усеченный список содержит всех друзей
В случае списка смежных вершин, напоминаю, это список из пар двух идентификаторов, требуется более сложный алгоритм. Каждый элемент списка, состоит из идентификатора «Кто?», идентификатора «С кем?», т.е. кто с кем имеет отношения. «Что?» у нас есть только в МоемМире. И для генерации списка мы должны взять полный список, и отфильтровать его по «Кто?».
Если у Пети ID пользователя это какое-то число, то мы должны отфильтровать спосок по этой компоненте, по этому числу.
Это самый простой алгоритм, и обратите внимание — он у нас требует перебрать все отношения между пользователями.
Понятно, что это нам не интересно. Это слишком долго будет.
Сложно → Список смежных вершин:
- Каждый элемент - (Кто?, С кем?, Что?, Следующий)
- Находим первый элемент с нужным Кто?
- Вытягиваем весь список
Поэтому рассмотрим оптимизированную версию, когда все связи одного пользователя ссылаются друг на друга.
Т.е. мы ищем, первую связь пользователя, Пети, узнаем, с чем он дружит, одного человека, и сразу получаем номер следующей записи,
т.е. таким образом мы сможем сгенерировать список друзей куда быстрее.
Масштабы
memory
Матрица смежности:
- Facebook: 28421 Петабайт
- ВКонтакте: 1136 Петабайт
- Мой Мир: 13642 Петабайт
- Toy net: 16 байт
Теперь давайте мы оценим, сколько потребуется памяти для этих представлений. Казалось бы, ничего сложного, список друзей.
Цифры ошеломляющие. Фейсбук, 500 миллионов пользователей, даже если ячейка занимает один бит, занимает 30 тыщ петабайт. Мне страшно от этой цифры. И естественно, для современной техники это решение не представимо, они слишком дорогие.
Т.е. мы еще на первом этапе, оценив объемы нашей системы, можем отсечь какие-то заведомо неверные решения. А эти решения, они достаточно напрямую отображаются на наши структуры данных.
Список смежных вершин (сложно):
- Facebook: 69 Гигабайт
- ВКонтакте: 14 Гигабайт
- Мой мир: 97 гигабайт
- Toy net: 200 байт
В случае списка смежный вершин, сложный вариант, напоминаю, устройство через список, объемы уже более реальные. Точный расчет, если кому-нибудь будет интересно, возникнут сомнения, можно меня в конце попросить, я покажу, как это считалось.
Ну, уже что-то похожее на реализуемую систему. Фейсбуку требуется 69 гигабайт, чтобы представить всех друзей, вКонтакте чуть поменьше, МойМир — чуть побольше, потому что там, связи сложные. А опять же, оценки делались исходя из цифры, что в среднем пользователи дружаться со 150 друзьями. Так как публичной информации нет, по поводу среднего числа друзей, и на этапе проектирования системы мы не можем эту цифру знать. Поэтому, приходится брать некоторую оценку. У кого-то друга, у кого-то пятьсот друзей, … такую оценку, иначе как с потолка, или из аналитических отчетов взять неоткуда.
latency
DDR3 ECC2 (DDR3-1066E):
- 8 гигабит в секунду максимум
- 8 гигабайт → $1500-2000
- Страница памяти → 4 килобайта
- 2 миллиона страниц в секунду
Давайте теперь оценим, сколько будет стоить тема, которая в состоянии хранить эти данные, в рамках одной машины, не прибегая к распределенным системам. Мы взяли топовую память, по скорости, DDR3 ECC2, ее пропускная способность 8 гигабит, стоит модуль $1500-2000, ну и можете себе представить, сколько будет стоить сервак, который будет работать с этой памятью.
Дальше идет важный такой момент, железного уровня. Когда мы говорим, что пропускная способность памяти восемь гигабит, т.е. один гигабайт в секунду, народ почему-то думает, что они могут эти восемь гигабит, получить при абсолютно хаотичном доступе, на то это и RAM, Random Access Memory, память со случайным доступом.
К сожалению, это не так. При обращении к памяти мы не можем прочитать произвольный байт. Память всегда читается постранично, одна страничка это четыре килобайта. И на самом деле, вот эти восемь гигабит, это не значит, что мы прочитаем нам нужный гигабайт, это означает, что мы можем в секунду прочитать два миллиона страниц, по четыре килобайта[1]. Это очень важный момент, который сильно влияет на дальнейшие выкладки.
Матрица смежности:
- Facebook: 16 rps
- ВКонтакте: 80 rps
- Мой мир: 40 rps
- Toy net: 2 000 000 rps
Давайте теперь представим, сколько запросов в секунду будет выдавать наш сервер. В случае матрицы смежности, допустим у нас есть сервер с таким объемом памяти, это получается… ну на такой памяти очень медленно. 16 запросов в секунду, 80, 40. Игрушечная сеть — два миллиона, ну в общем, один запрос — одна страницу.
Это решение нам не интересно, оно слишком дорогое.
Масштабы: memory/latency Список смежных вершин (просто)
- Нет смысла рассматривать, full scan
Простой вариант со списком смежных вершин, где мы делаем полный скан всех отношений, нам тоже не интересен. Потому что он неэффективен.
Список смежных вершин (сложно):
- 150 друзей у каждого в среднем
- 150 страниц на генерацию списка
- Итог: 14 000 rps
А сложный вариант, где все отношения связаны с друг с другом, для каждого пользователя, они позволяют, они требуют сделать…
напоминаю цифру — 150 друзей в среднем, т.е. для каждого пользователя нам нужно сделать 150 чтений памяти, причем случайных.
И это означает, что мы не 150 элементов прочитаем, а прочитаем на самом деле 150 страниц памяти, т.е. не какие-то байты,
а 100500 сто пятьдесят страниц, каждая по четыре килобайта.
Получается, что мы на нашем топовом железе можем выдать максимум 14 тысяч запросов в секунду.
Зачем я долго рассказывал вам про байты, странички и так далее?
Обратите внимание, мы можем выжать на топовом железе 14тысяч запросов в секунду, а изначальные требования — пять миллионов запросов в секунду для фейсбука.
Ну это все как бы очевидно, можно было так долго не говорить, но нужно было почувствовать порядок. Т.е. у нас производительность на топовом железе в пять тысяч раз не дотягивает до желаемого.
Логичный вывод — нам придется строить распределенную систему, нам не избежать проблем, даже на такой простой задаче. Более сложные задачи требуют, естественно, еще более сложных решений.
Я беру максимальную пропускную способность памяти, я беру минимально необходимый объем оперативной памяти, и все равно мы не укладываемся на порядки. Исходя из этого, кстати, можно оценить, например, сколько серверов стоит в mail.ru, или там у facebook-а, в лучшем случае.
Оптимизация матрицы смежности
- Матрица смежности сильно разряжена
- Можно производить адаптивную упаковку
- Реализация станет сложней
Давайте рассмотрим еще паручку простых оптимизаций. Матрица смежности — это таблица «пользователи/пользователи», ячейка — отношения между ними. Она у нас сильно разряжена. Потому что мы храним по сути, отношения пользователя для каждого с каждым, а он дружит естественно не со всеми, а с каким-то подмножеством, в среднем — 150 человек. Это означает, что у нас очень большие элементы матрицы — пустые, и мы можем делать сжатие, т.е. пустые регионы выкидывать. Памяти у нас потребуется меньше, но появляется проблема фрагментации, код сильно усложняется. Т.е. для оптимизации, чтобы уменьшить объем потребляемой памяти, нам приходится идти на уступки. С усложнением кода. Вместо простой структуры, мы имеем что-то сложное. Чем сложнее код, тем дольше его разрабатывать и отлаживать. Тем больше с ним проблем, тем более непредсказуемо он себя ведет.
Оптимизация списка смежных вершин
- Список смежных вершин можно группировать по "Кто?"
- Возрастёт потребление памяти
- Реализация станет сложней
Оптимизация списка смежных вершин, ну вот, мы уже одну применили, связали все в список, можно еще сделать группировку данных. Когда для пользователя Пети, все его связи лежат рядышком. Проблемы те же самые. У нас возрастет потребление памяти, потому что для каждого пользователя придется резервировать место для его новых друзей. Нам придется производить какую-то переупаковку данных, т.е. возникает проблема, это становится тоже сильно сложнее.
Кирилл Коринский: А давайте вопросы в конце?
Олег Царев: Информацию о следующей связи конечно хранить не придется, однако нам придется резервировать место, посколько для одного пользователя нужно хранить связи рядышком, а у одного пользователя много друзей, а у другого — мало. А если не поместилось? А если осталось пустое пространство? Это очень большая проблема в разработке. Лучше не станет, если хотите, можем посмотреть более подробно в конце.
Ну, с друзьями все понятно, мы имеем классическую проблему выбора между памятью и задержками. Т.е. либо мы имеем большую память и какие-то задержки, иногда приемлимые, иногда не очень.
Либо мы памяти тратим меньше, но все равно у нас есть проблема задержек. Memory и Latency это две первые такие точки экстремума, между которыми надо выбирать. И третья, неявно рассмотренная — это сложность кода. У нас здесь компромисс — потребляемая память, задержки, сложность кода.
Видео
Постановка задачи
- Существуют различные кодеки
- Разные характеристики:
- Размер ролика
- Потребляемая при конвертации память
- Количество вычислений при конвертации
- Качество записи
Можно рассмотреть другую задачу. Видео. YouTube. Пользователь загружает данные на сервер, они там должны хранится, и раздаваться ему по требованию. Потом будет доклад Макса Лапшина, кстати, это один из разработчиков ErlyVideo, кстати, с ним можно будет еще на эту тему поговорить, какие там возникают проблемы.
Мы рассмотрим крайне упрощенную ситуацию. У нас есть различные кодеки. Кодеки — это алгоритмы сжатия видео. И эти кодеки, имеют опять же, отличные характеристики. У нас снова встает проблема выбора, между тем, сколько ролик будет занимать, сколько он будет конвертироваться, сколько вычислений потребуется сделать, для конвертации. Он может конвертировать долго, но мало потреблять, с другой стороны мы можем конвертировать быстро, но потреблять процессор гораздо больше.
Видео: решение
- Несжатое видео
- H.264
Мы рассмотрим два самых простых случая. Это несжатое видео, это просто 24 кадра в секунду, и один из новых кодеков, весьма эффективный, H.264.
Видео: «Экстремумы»
- CPU-limited
- H.264 требует много вычислений.
- Memory-limited
- Несжатое → много памяти для хранения
- Latency-limited
- Несжатое → много памяти для хранения
- H.264 → время на конвертацию
И снова у нас возникает та же самая проблема. Проблема выбора. H.264 требует весьма трудоемких вычислений, т.е. каждое загружаемое пользователем видео придется конвертировать. Т.е. нам требуются процессорные мощности, нам недостаточно просто памяти, нам нужен еще быстрый процессор. Но с другой стороны, несжатое видео требует очень много памяти для хранения. И в зависимости от используемого кодека у нас будет совершенно разное железо. Совершенно разный бюджет. Но помимо этих двух аспектов, CPU и Memory, у нас снова возникает проблема Latency, это задержки. В случае несжатого видео, у нас будет проблема чтения, загрузки роликов с сайта. Чем больше занимает ролик, тем дольше пользователь его загружает, у него может быть маленький канал, и так далее. Но в случае H.264 потребуется больше времени на конвертацию.
Мы снова сталкиваемся с проблемой компромиссов — что мы хотим?
Если у нас, например, идет какая-то обработка, рендеринг видео на кластере, фильм например, у нас сеть очень быстрая, и мы можем работать с несжатым видео. Если у нас именню YouTube, то раздача видео по тонким каналам конечным пользователям, то нам, конечно, естественно, чтобы видео кушало поменьше.
Видео: выводы В задаче с видео тоже есть «экстремумы»
- Каждое из решений имеет свои минусы
- Три точки экстремума: CPU, Memory, Latency.
А выводы вполне очевидны. Нам приходится опять выбирать, и нет идеального решения. Каждое решение зависит от вашей задачи. И в зависимости от вашей задачи, меняется требование к аппаратуре.
Основные оси
- CPU
- Memory
- Latency
- Сложность
Если это все подытожить, мы видим следующую картинку. У нас есть несколько ресурсов. Процессор, память и задержки. Еще важный критерий — для конкретно разработчиков, для инженеров сложных систем — это сложность кода. Чем сложнее в нем разбираться, дольше исправлять ошибки, дольше разработатывать какие-то новые фьючерсы, ну и собственно, проект становится менее управляемым, риски управления возникают.
Производные оси
- Бюджет проекта
- Сроки
- Опыт разработчиков
- Аппаратура
- Имеющиеся инструменты
С другой стороны, здесь есть оси, которые я называют производные, производные с точки зрения инженеров, для менеджмента они наоборот первичны. Это собственно бюджет проекта, от него зависит, какую мы можем нанять команду, насколько она много будет уметь, это опыт разработчика на этом слайде. От этого зависят сроки разработки, чем более крутых разработчиков мы нанимаем, тем быстрее они делают систему.
От этого зависит опять же аппаратура. Если сделать решение влоб, которое работает опять таки на десяти друзьях, — для этого и пример приведен («У нас все работает быстро»). Когда пользователей становится несколько тысяч, требуется уже мощный сервер. Для миллионов пользователей это решение не работает вообще. Ну и очень важным момент в нашем докладе, какие у нас есть инструменты, чем они нам помогут.
Эта первая часть подводит к очень важному вопросу — не бывает универсальних хранилищ, не бывает универсальных решений. Серебрянной пули нет. Вам всегда придется искать и думать, какая у вас задача, и какие взять решения.
Выводы
- Основная задача HighLoad — поиск локального оптимума.
- Иногда задача не разрешима в имеющихся условиях
- Наша цель — познакомить слушателей с ключевыми факторами
Можно сформулировать тезис, один из ключевых тезисов доклада. Задача инженера сложных систем, это найти компромисс, между всеми требованиями. Это также задача и менеджмента, и также задача инвестора, это задача всей команды, которая разрабатывает систему.
Это нужно у себя держать в голове. Самое главное — это конечно, цель.
И надо понимать — иногда мы не можем разработать Фейсбук на старом дедушкином сервере. Это не будет работать. Я и в сетевых дискуссиях, и на докладе своем как-то наблюдал, что люди почему-то не задумываются про эти моменты. Не понимают их важность. Именно поэтому я рассмотрел «проблему с друзьями».
Ключевые факторы, влияющие на выбор решения, я упомянул.
Мы поняли, что нам придется строить систему распределенную, и искать компромисс.
Дальше в следующей части Кирилл рассмотрит, чем эти системы характеризуются, и на что нужно обращать внимание, при выборе хранилища под ваши задачи.
Кирилл Коринский: А может у кого-нибудь есть вопросы, по тому, что рассказал Олег? Просто дальше мы уйдем совсем в другие дебри, и вы можете их забыть.
Олег Царев: Я охотно допускаю…
Было высказано замечание, что кодек h264 конвертирует достаточно быстро. Я охотно верю. Я не разбираюсь в видео вообще. Я это взял просто как пример, в качестве иллюстрации. Это игрушечный совершенно пример, его цель — познакомить с проблемами.
Во-первых, я хочу спросить, сколько попросит разработчик, который знает, что такое BTree-дерево?
Это стандартный алгоритм, но я знаю очень немного людей, которые понимают, что такое btree. Для примера — в аналитической базе, которую я разрабатывал два года назад, BTree-деревья писались четыре года. И спустя четыре года мы в них находили ошибки.
Кирилл Коринский: А к вам такой вопрос — вы сами пробовали реализовать btree-дерево?
Олег Царев: Я собственно реализовывал btree-дерево.
Ну объемы данных были 200-300 Гигабайт.
Еще вопросы?
Эти 64-128 это на самом деле немного другие цифры. Это ассоциативность кеша процессора, а я говорю про шину памяти.
Нет, естественно мы вычитываем один и тот же объем. Просто когда мы последовательно вычитываем данные, мы всегда в рамках одной страницы вычитываем четыре килобайта. В случае random access доступа, нам придется выкидывать большую часть этих данных.
Если вы читаете по одному байту из каждой страницы, то да, это будет в 4000 раз медленнее.
Есть такая хорошая книжка Криса Касперского, «Техника оптимизации программ. Эффективное использование памяти», там это рассматривается.
Давайте я это обсуждение на потом отложу. Еще вопросы?
 Андрей Аксенов:
У меня ответ на предыдущий вопрос. Пока ты все это рассказывал, я написал benchmark и померял случайный доступ к памяти, по 512 байт, что достаточно для хранения 128 друзей с сырьем, или пятисот с … У меня получилось 3 миллиона запросов в секунду, ты ошибся в 200 раз в своих оценках, это раз.
И два — память действительно работает не по четыре килобайта, а существенно меньшими цепочками
Андрей Аксенов:
У меня ответ на предыдущий вопрос. Пока ты все это рассказывал, я написал benchmark и померял случайный доступ к памяти, по 512 байт, что достаточно для хранения 128 друзей с сырьем, или пятисот с … У меня получилось 3 миллиона запросов в секунду, ты ошибся в 200 раз в своих оценках, это раз.
И два — память действительно работает не по четыре килобайта, а существенно меньшими цепочками
Олег Царев:
Я бы хотел немного процитировать этот момент.
Я взял естественно ограниченный случай, нас очевидно интересует не страница памяти, 4Кб, она попала в кеш процессора, дальше мы работаем с кешом процессора и…
Андрей Аксенов:
Олег, я повторяю, я за-mallocнул буфер на полгигабайта, и сделал миллион запросов со случайным смещением, по полкилобайта каждый.
Это работает на скорости 3 миллиона запросов в секунду. … дальше я это просуммировал…
Олег Царев:
Давайте мы рассмотрим этот тест отдельно, если останется время.
Сейчас Кирилл начинает к сожалению.
Андрей Аксенов:
… Твои оценки неправильные, в две сотни раз.
Олег Царев:
Это мы обсудим после доклада.
Что такое распределенные хранилища
Виды партицирования
- Функциональная декомпозиция
- Горизонтальное партицирование
- Вертикальное партицирование
Кирилл Коринский:
Так вот, кончились всякие теоретические вещи, в смысле рассуждения, теперь начинаются достаточно сложные и теоретические вещи.
Во-первых, кто-то знает в зале, что такое партицирование?
Ладно. Поехали.
Партицирование можно делать несколькими способами.
Первый — это функциональная декомпозиция.
Олег Царев: Кирилл, расскажи пожалуйста, что такое партицирование. Знает достаточно мало народу, что это такое.
Кирилл Коринский:
Фактически, это распределение данных, когда ты разрезаешь свои куски данных, каким бы то ни было образом, по узлам твоего кластера.
Для примера можно представить базу данных, когда данные не влезают в одну таблицу, по объему на сервере.
Или если они влезут в одну таблицу performance будет падать, соответственно, делаешь горизонтальное партицирование,
раскидывая разные строчки.
Также можно делать вертикальное партицирование, раскидывая просто по колонкам.
Олег Царев: Ну тут наверное, я немного прокомментирую все-таки, партицирование — это просто разделение данных, а не страшное слово, в результате,
партицирование — это когда мы разделяем данные на части.
Кирилл Коринский:
Именно горизонтальное, именно целостные данные, куски, именно строчки. В базе данных мы будем разделять именно строчки.
Олег Царев:
Да, горизонтальное партицирование — это разделение отдельных компонент.
В случае с друзьями, можно сказать, что горизонтальное партицирование, это у нас половина наших связей,
а вертикальное партицирование, это когда мы «Кто?» и «С кем дружит?» разносим на разные узлы.
Кирилл Коринский:
Также есть функциональная декомпозиция, это когда партицирования, как такового нет, но вы это делаете просто руками, тем или иным образом.
Manual partitioning
- Разделяем данные на уровне
приложения
- Требует дополнительной работы
- Теряется транзакционность
Что такое разделение руками? Это разделение данных на уровне приложения, мы пишем некую систему, которая каким-либо образом определяет в какое из нескольких хранилищ будут направлятся наши данные. Есть такое понятие, distributed artifaction, вот он фактически и есть.
Automatic partitioning
- Тяжело поддержать на уровне хранилища
- Приходится указывать критерии партицирования
- Универсальные критерии не работают
Иные аспекты партицирования
- На каждом узле выбирается:
- Аппаратура
- Хранилище
- Операционная система
- В случае HDD хранилища: файловая система
Репликация
- Master-Master
- все узлы равноправны
- Master-Slave
- главные и ведомые узлы
Транзакции
- offline
- Для клиента транзакция завершается
после исполнения на текущем узле текущем узле.
- online
- Для клиента транзакция завершается
после исполнения на всех узлах всех узлах.
![]() Тут случилось горе, идиоты-операторы видимо сделали 10-минутную паузу в записи.
Рано или поздно мы заполним стенограмму (когда у докладчиков найдется время), а
пока рекомендуем по теме, рассмотренной в пропущенном блоке небольшую статью
CAP-теорема Брюера, совершенно случайно тоже от участника ADD-2010.
Тут случилось горе, идиоты-операторы видимо сделали 10-минутную паузу в записи.
Рано или поздно мы заполним стенограмму (когда у докладчиков найдется время), а
пока рекомендуем по теме, рассмотренной в пропущенном блоке небольшую статью
CAP-теорема Брюера, совершенно случайно тоже от участника ADD-2010.
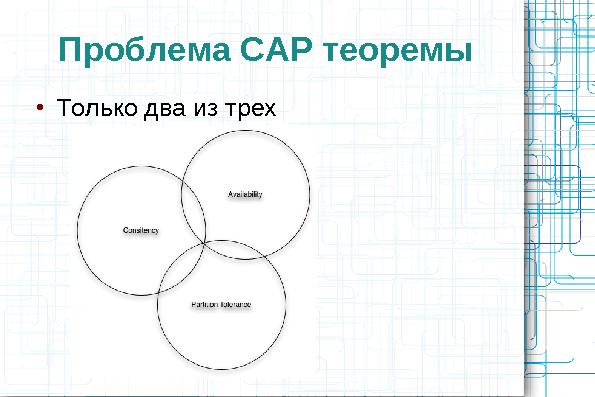
- Consistency
- Система всегда выдает корректные, непротиворечивые, ответы.
- Не может быть так, что после записи данные потерялись.
- Не может быть так, что один и тот же запрос к данным (выборка данных, поиск, и т.д.) в зависимости от узла
выдавал различные данные.
- Availability
- Система обязана выдавать всегда выдавать ответы — независимо от аппаратных сбоев отдельных узлов.
- Partition tolerance
- Система продолжает работать корректно при недоступности части узлов.
Пример:
- +A +C -P
- Обычная СУБД
Обычная СУБД данные которой лежат на одном сервере. Она не может стать неконсистентной, а данные читает только с одного storage к которому она имеет монопольный доступ.
Пример:
- +С +P -A
- Система с online транзакциями
Система с несколькими мастер-базами, которые обновляются синхронно. Она всегда корректна, потому что транзакция отрабатывает, только если изменения удалось распространить по всем серверам БД.
Она продолжает корректно работать по крайней мере на чтение, если один из серверов падает. А вот попытки записи будут обрываться или сильно задерживаться, пока система не убедится в своей консистентности.
Пример:
- +A +P -C
- Система с offline транзакциями
Система с несколькими серверами, каждый из которых может принимать
данные, но не обязуется в тот же момент распространять их по всему
кластеру.
Система переживает падения части серверов, но когда они входят в строй, они будут выдавать пользователям старые данные.
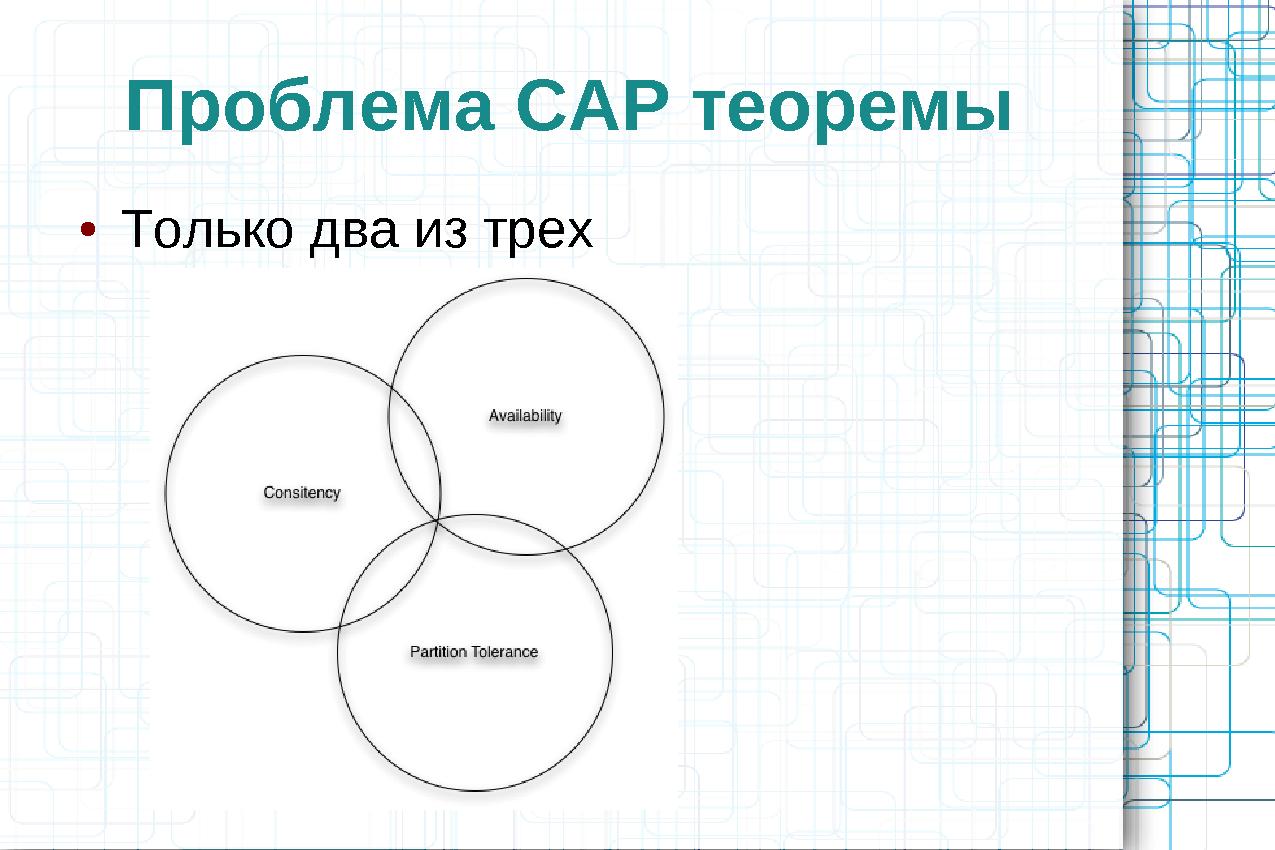
CAP теорема постулирует, что система может удовлетворять только двум требованиям из трех. Существует формальное математические доказательства этого.
Данную проблему невозможно избежать.
Инженерам highload систем приходится искать компромисс.
Как он выглядит?
CAP Solution
- Жертвуем Consistency
- Разбиваем систему на части
- CAP теорема работает в каждый момент времени
Первый вариант, пожертвовать, например, Consistency. Тем самым в случае потери комментариев, за последние пару минут, мы не получим, какой-то сильной проблемы.
Мы можем развить этот вариант и составить систему, которая будет кускам удоволетворять разным свойствам CAP теоремы. Например, комментарии будут жить в +A+P-C, а финансы -A+P+C.
Но наиболее интересным вариантом является понимание, что CAP теорема накладывает на систему ограничения в определенный момент времени. В другой момент она может иметь отличные свойства.
Interface: access
- Library
- клиентская библиотека
- ODBC
- стандартный интерфейс доступа
- Embedded
- встраиваемая база
- Telnet
- простой сетевой протокол
Олег Царев:
Один из самых важных моментов, это интерфейс…
Кирилл Коринский:
Маленькая ремарка — остались примерно те, кто поднимал руки, что знают, что такое репликация, CAP-теорема…
Олег Царев:
Ну тут у нас будет запись, интересующиеся смогут посмотреть.
Лицо базы — это ее интерфейс.
Способ, которым мы получаем данные, или делаем поиск, запускаем запросы.
И именно вокруг этого потом ломаются копья.
SQL или NOSQL?
Это одна из причин, по которой мы делам совместный доклад.
Чтобы не было ангажированности в пользу того или иного решения.
Интерфейс у нас грубо говоря можно разделить на четыре части.
Это некоторые клиентские библиотеки, фактически все базы их имеют.
Это стандарт ODBC, который для Microsoft SQL-сервера, потом для других баз.
Embedded базы, встраиваемые, т.е. в которой движок базы напрямую интегрируется в ваше приложение. И некоторый простой текстовый протокол. Telnet. Вплоть до того, что можно к хранилищу…
Кирилл Коринский: Маленькая ремарка, есть базы, например тот же memcache, к которому по другому просто не прицепишься. Или тебе надо использовать сторонние какие-то клиенты, база сама предоставляет только один простой протокол (citilog?).
Олег Царев:
Ну да, прицепились telnet-клиентом, посылаем обычные текстовые команды, получаем читаемый текстовый ответ.
Interface: method
- API
- интерфейс доступа
- DSL
- domain-specific-language
- SQL (суть DSL)
- structured query language
Помимо, собственно, способов подключения, у нас есть еще вопрос, как собственно выглядит взаимодействие с базой. Т.е. это может быть API, это может быть некоторый набор функций, куча классов для работы с базой, это может быть какой-то специализированный язык. Эти языки называются Domain Specific Language, DSL. Языки разработаны под какую-то конкретную задачу. Т.е. мы на SQL-е не можем сделать отдельное вычисление, объявляет ли он себя как Тьюринг-полный? — это хороший вопрос. Мы не можем на нем написать произвольную программу. Но мы на нем можем сделать любую выборку данных. Именно поэтому, … кастомизированы.
Самый популярный — SQL, остальные все языки достаточно местечковые. Следующий вопрос — это то, насколько полно мы работаем с данными. Одни данные позволяют делать нам только поиск, такие как Sphinx, другие позволяют делать полноценные запросы.
Interface: abstraction level
- Search
- поиск и выборка значений по ключу
- Query (Search included)
- поиск, выборка и обработка значений
Мы не просто просим из достать какие-то данные, мы просим их сделать с ними какие-то вычисления. Зачем нам это нужно?
Во-первых, для удобства. Мы написали один запрос и получили обработанный результат, например, статистику.
Во-вторых, часто это быстрее. Если нам например нужна сумма в какой-то колонке, движки умеют оптимизировать такие вычисления. При этом вычислять ее во время добавления данных.
Обзор доступных хранилищ
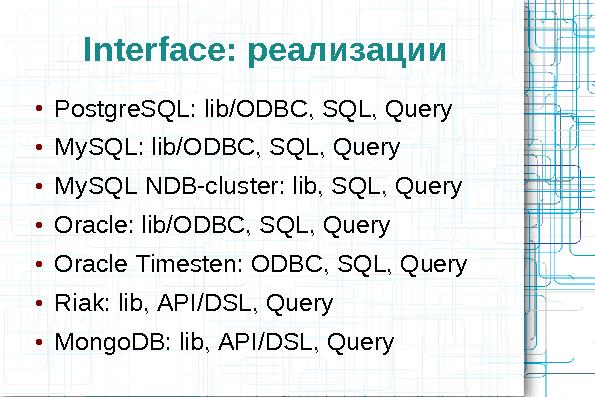
Interface: реализации
- PostgreSQL
- lib/ODBC, SQL, Query
- MySQL
- lib/ODBC, SQL, Query
- MySQL NDB-cluster
- lib, SQL, Query
- Oracle
- lib/ODBC, SQL, Query
- Oracle Timesten
- ODBC, SQL, Query
- Riak
- lib, API/DSL, Query
- MongoDB
- lib, API/DSL, Query
- Hadoop
- lib, API, Query
- Mnesia
- embedded, DSL, Query
- memcached
- telnet, DSL, Search
- memcachedb
- telnet, DSL, Search
- berkleydb
- embedded, API, Search
- voldemort
- lib, API/DSL, Query
- cassandra
- lib, API/DSL, Search
У нас тут есть обзор, я думаю, лучше просмотреть слайды. Мы свели все реализации воедино, у популярных баз, и вы можете под ваши задачи выбрать, что вам интересно. Т.е. какой-нибудь критерий, упомянутый ранее.
В частности, это еще интересно при интеграции между базами данных.
Storage
- RAM
- все данные находятся в оперативной памяти
- Filesystem
- система использует для хранения файлы
- Raw partition
- система использует раздел диска
Следующий вопрос — это storage, где данные находятся. Это очень сильно влияет как на эффективность работы, так и на другие характеристики, такие как консистентность. Тут достаточно все просто. Оперативная память, файловая система, и голый раздел на диске. Сетевые хранилища мы не рассматриваем, потому что они описываются как распределенная система в нашем обзоре. А для них тоже самое верно.
Storage: реализации
- PostgreSQL
- FS, RAM
- MySQL
- FS, RAM
- MySQL NDB-cluster
- RAM
- Oracle
- Raw, FS, RAM
- Oracle Timesten
- RAM
- Riak
- FS, RAM
- MongoDB
- FS
- Hadoop
- FS
- Mnesia
- FS, RAM
- memcached
- RAM
- memcachedb
- FS
- berkleydb
- FS, RAM
- Voldemort
- FS, RAM
- Cassandra
- FS
Большинство баз у нас умеет работать с файловой системой, отдельные базы живут только в памяти.
Persistent
- Полная (full)
- данные гарантированно не теряются
- Частичная (partial)
- может потеряться последние несколько транзакций
- Отсутствует (loose)
- данные не сохраняться вообще
Следующий важный вопрос — это persistence, это как данные хранятся, насколько долго они хранятся.
Например, для кеша root-сервера, мы можем данные терять, это последняя строчка, когда persistence отсутствует, нам не страшно потерять данные. Полный persistence, это когда мы считаем денежные транзакции, мы не имеем права терять деньги клиентов. И есть еще такое понятие, как частичный persistence, он может применятся в системах, когда мы можем потерять несколько последних записей. Зачем он нужен? Ну потому, что он работает быстрее, чем полный persistence.
Persistent: реализации
- PostgreSQL
- full
- MySQL
- full, partial
- MySQL NDB-cluster
- partial, loose
- Oracle
- full, partial, loose
- Oracle Timesten
- partial, loose
- Riak
- full, loose
- MongoDB
- full
- Hadoop
- full
- Mnesia
- full, loose
- memcached
- loose
- memcachedb
- full
- berkleydb
- full, partial
- Voldemort
- full, loose
- Cassandra
- full
Тут у нас есть сводная таблица, большинство поддерживают либо loose, либо полный persistence. Только Oracle поддерживает все три части одновременно.
Динамическая типизация
- Гетерогенный доступ
- Единообразный доступ
И следующий, очень важный вопрос, это типизация. Типизация — это некоторые типы, некоторые свойства наших данных. Мы либо указываем явно, например, мы указываем в SQL время колонок, либо типы сопоставляются во время вычисления. Т.е. мы создали таблицу и описали — здесь у нас числа, а здесь у нас строки.
А в Javascriptе мы работаем с данными исходя из контекста. Вот динамическая типизация, это как раз случай, когда мы не знаем заранее, типы данных, с которыми мы работаем. Они могут быть любые. Из плюсов это то, что мы можем в одной таблице[2] хранить и тексты и строчки и все подряд.
Это например, интересно для блогов, для постов. У нас там могут лежать и картинки, могут лежать тексты, а может быть там какая-то очень сложная структура даже. Например, либо HTML, либо Plain-текст. И удобно это тем, что у нас, в принципе, обработчик всегда один. Мы обрабатываем данные и всегда проверяем, какой у нас здесь тип. Если это строка, то мы ее выводим, если это картинка, то мы ее рисуем.
Статическая типизация
- Целостность данных
- Высокая производительность
- Экономия памяти
У статической типизации, за которую часто ругают SQL, где нам нужно явно указывать типы, у табличек, у колонок, у индексов, — у них есть другие, очень важные плюсы.
Во-первых, это целостность данных. Если мы знаем, что число — всегда число, база нам не даст записать строчку… Например, пользователь вместо номера паспорта при покупке билета указал имя и фамилию. Понятно, мы проверяем это еще при вводе, но если вдруг, программист сделал ошибку, мы все равно не сможем все это записать. Система проверяет это автоматически. И на самом деле, система со статической типизацией более производительна.
Нам не нужно сохранять информацию о типе, в каком-то виде, мы ее знаем заранее. Она описана сбоку, как схема базы.
Кирилл Коринский: Маленькая ремарка. Почти все nosql-базы, которые мы рассматриваем здесь и сейчас, имеют динамическую типизацию. И они имеют только один тип — строка.
И вам приходится жить с этой строкой, и самим сериализовать в нее структуры данных, ну и возращать их назад.
Олег Царев: И самим вам делать обработку ошибок.
Кирилл Коринский:
Десериализацию и сериализацию вы делаете сами.
Олег Царев:
… Запись и чтение. Вам приходится проверять ошибки самостоятельно, на уровне приложения.
Кирилл Коринский:
Какие ошибки?
Олег Царев:
Ну, например, у нас вместо строки оказалось число.
Если нам нужна смешанная типизация, для половины данных статическая, для половины — динамическая, то придется выбирать между ними.
Либо вообще брать разные движки, для разных частей системы.
Реализации
- PostgreSQL
- Статическая
- MySQL
- Статическая
- MySQL NDB-cluster
- Статическая
- Oracle
- Статическая
- Oracle Timesten
- Статическая
- Riak
- Динамическая
- MongoDB
- Динамическая
- Hadoop
- Динамическая
- Mnesia
- Динамическая
- memcached
- Динамическая
- memcachedb
- Динамическая
- berkleydb
- Динамическая
- Voldemort
- Динамическая
- Cassandra
- Динамическая
Тут в принципе рассмотрены почти все SQL-базы …
Cost/license
- PostgreSQL
- BSD-like
- MySQL
- GPL 2.0/just call
- MySQL NDB-cluster
- GPL 2.0/just call
- Oracle
- $47,500
- Oracle Timesten
- $41,500
- Riak
- Apache 2.0
- MongoDB
- AGPL 3.0
- PostgreSQL
- BSD-like
- MySQL
- GPL 2.0/just call
- MySQL NDB-cluster
- GPL 2.0/just call
- Oracle
- $47,500
- Oracle Timesten
- $41,500
- Riak
- Apache 2.0
- MongoDB
- AGPL 3.0
Следующий важный вопрос — это стоимость и лицензии. Лицензии нам важны при разработке нашего софта, чтобы у нас не было каких-то проблем в суде…
Кирилл Коринский: … они важны, когда ты хочешь понимать, хочешь ли ты вводиться эту базу, и на каких условиях ты хочешь в нее вводиться, что последует после этого.
Если ты хочешь например, взять Postgres, и сделать его embedded — пожалуйста.
А если он сменит лицензию на GPL, как MySQL, то после того, как ты его сделаешь embedded, и встроишь к себе, тебе придется открывать свое решение.
Не все люди на это согласны и способны.
Олег Царев: Да, например, тот продукт, который я разрабатываю, это сервер, который сделан на базе MySQL, весь наш исходный код доступен на сайте, именно по причине лицензий. И если мы включаем патчи с другими лицензиями, например, BSD, мы вынуждены указывать сopyright, что этот патч имеет другую лицензию.
Если мы обмениваемся с Oracle какими-то патчами, то опять же, приходится эти вопросы улаживать.
Может быть в России народ не очень с этим знаком, а на западе это очень важный вопрос.
Ну и естественно, что важна цена. Сколько нам будет стоить решение.
Кирилл Коринский:
И еще маленький вопрос, даже ремарка. Есть такая база BerkleyDB.
Вообще она бесплатна. В большинстве своем случаев.
Но есть такие вкусные вещи, как репликация, и цена этой репликации — десять тысяч долларов.
Если посмотреть на этот слайд, на TimesTen за сорок тысяч долларов, которая работает, и на Berkley Database, который еще надо допиливать, возникает вопрос…
Олег Царев: Да, если у нас есть время, можно допилить BerkleyDB… если времени нет, берем TimesTen, и как говорится, не паримся.
Это опять же, насколько решение готово, от этого зависит цена.
Да.
Кирилл Коринский:
А теперь смотри, если используешь какой-то код из MongoDB, заголовочный или еще что-то такое, ты должен открывать и исходный код своего приложения, с которым ты слинковал.
Тогда я тебя приветствую. Тогда ты пойдешь в суд, ты или твой…
Олег Царев: Есть еще способ сделать это в виде загружаемой библиотеки, но это вообще говоря, хороший вопрос к лицензиям. Разные лицензии требуют по-разному интегрировать ваши продукты.
Кирилл Коринский:
Ну ты можешь сделать такую вещь — отреверсинженирить его драйвер, и попросить своего друга… использовать любую удобную тебе лицензию.
Олег Царев:
Не будем отвлекаться, но вопрос лицензий он на самом деле очень интересный и важный.
Кирилл Коринский:
Они могут продать тебе по той цене, о которой ты договоришься, и на нужных тебе условиях.
Олег Царев:
Oracle требует передачи авторских прав, перед передачей патча.
Это потому, что…
Авторское право.
Когда ты работаешь наемным сотрудником, ты же передаешь все права на свой код работадателю?
Да, действительно…
Oracle выпускает две версии MySQLа, первая — это open-source, GPL-версия, вторая — это закрытая версия, с некоторыми дополнительными фичами.
Продукты производные, такие как MariaDB, или PerconaServer, они базируются на GPL-версии, и работают через патчи.
А закрытая версия — это собственность только Oracle, он имеет право делать все, что угодно, любые изменения, не открывая исходный код.
Счастья нет
- У каждой задачи свои требования
- У каждого хранилища свои сильные и слабые стороны
- Хранилище под задачу, а не задачу под хранилище
- Одного хранилища мало
- Правильное решение всегда компромисc
Теперь перейдем собственно к выводам, подытожим. Сначала Кирилл скажет свои выводы, потом я еще дополню.
Кирилл Коринский:
Выводы на самом деле простые. У каждой задачи свои требования.
Вполне очевидно, что требования у нас разные, от разных задач.
Олег Царев:
Деньги мы считаем — у нас одни требования по надежности, когда мы показываем картинки вКонтакте или на Фишки, у нас другие совершенно требования.
Кирилл Коринский:
Нет, требования и желания у нас одни и те же, но реально приходится…
Олег Царев:
Реально приходится искать компромисс.
Нет универсального хранилища.
Кирилл Коринский:
Стоит понимать, что у каждого хранилища свои плюсы и минусы,
есть некоторое окружение, в котором тебе приходится выбирать, что тебе хватит денег, что тебе позволит включить юридически…
Олег Царев:
Все аспекты, которые мы рассматривали, работают одновременно.
Кирилл Коринский:
Не только хранилище под задачу, а еще некоторые условия, которые у тебя сейчас есть, т.е. ты в них живешь.
Очень может получится, что одного хранилища мало, потому что одни хранилища лучше делают одно, другие хранилища лучше делают другое,
и получается что нужно делать разные хранилища и пытаться как-то между ними жить.
Олег Царев:
Надеюсь наш доклад отвечает на один простой вопрос, какое хранилище выбирать?
Счастья нет. И требуется привлекать менеджмент, требуется привлекать аналитиков, юристов и разработчиков, чтобы выбрать решение под вашу задачу.
И именно поэтому, у нас есть работа. Именно поэтому, IT — востребованная специальность на рынке труда, нужны люди, которые умеют решать такие задачи, находить этот компромисс. Серебрянная пуля — это компромисс.
Вопросы
См. видеозапись с 43:54.

Примечания
- Сравнительный анализ хранилищ данных (Олег Царев и Кирилл Коринский на ADD-2010)
Был на первой половине рассказа. Говорили, как работать с большими объемами данных. В качестве примера была выбрана задача по хранению друзей в социальной сети. Итог я не запомнил, но всем было очевидно, что хранить надо проиндексированный список ребер.
Привели вычисления скорость работы памяти, при это из-зала говорили другие цифры, утверждая, что память может читать и более мелкие порции, чем одна страничка (4K).
По ходу доклада было много определений и даже утверждений: транзакция, репликация, CAP-теорема. Мне первая часть не очень понравилась, думаю, с такой темой можно было много интересного рассказать.
- Сравнительный анализ хранилищ данных (Олег Царев и Кирилл Коринский на ADD-2010)
Тонкий (Царев) и толстый (Коринский) не торопясь, даже сонно по очереди вещали о проблемах хранения данных.
Центральный тезис доклада — универсального хранилища нет. Начали с простого примера: получение списка друзей в социальной сети на примере Facebook, ВКонтакте, еще чего-то и игрушечной соц. сети. Докладчики приводили оптимистические оценки объемов данных матрицы смежности. Из расчета, что среднем один пользователь имеет 150 «друзей» для Facebook’а получилось около 2800 ПБ.
Далее докладчики примерялись к производительности топового сервера, учитывая жуткие технические подробности скорости доступа к оперативной памяти. И пришли к выводу, что такой сервер сможет обработать всего 14 тысяч запросов в сек. А надо 500 млн. Ну, значит, надо замутить распределенную систему… Еще немного порассуждали о четырехугольнике CPU-memory-latency-сложность кода.
Кто-то в зале (кажется, Андрей Аксенов) громко заявил, что докладчики ошиблись на два порядка, и все не так уж плохо.
Затем поговорили о partitioning и перешли к CAP-теореме. Все шло медленно, с подробным объяснением элементарных и не очень вещей.
Доклад был рассчитан на полтора-два часа, и я сбежал послушать Бибичева.
Оценка: нормально, но можно и лучше (динамичнее).
- Сравнительный анализ хранилищ данных (Олег Царев и Кирилл Коринский на ADD-2010)
Я сперва думал что это будет про SAS/NAS/SAN'ы. Оказалось – нет, это про «SQL и NoSQL» - тема, которая звучала на конференции очень часто. Может быть, даже слишком часто.
Два «классических программиста» – один пухлый и лохматый, другой тощий, и оба в майках (в отличие от костюмчика из IBM). Олег Царев и Кирилл Корецкий – два этих голоса мы слышали на протяжении двух дней тоже очень часто. Может быть, даже слишком часто.
Презентация также представляла собой печальный образец того, что чаще всего приходилось видеть на конференции – белый фон, черные bullet’ы. Программисты – явно не мастера подать результаты своей работы.
Докладчики рассматривали задачу анализа большого объема данных на примере Facebook'а и других социальных сетей. 500 миллионов пользователей, 5 миллионов запросов в секунду – действительно, потрясающие воображение показатели. Нам очень долго объясняли, почему это никак не получится обработать на одном компьютере. Доказывали, можно сказать, с цифрами в руках.
Докладчики ввели для слушателей несколько корявых определений, попутно споря друг с другом о формулировках. Потом на основе этих определений дали CAP-теорему. Теорема гласит, что для распределенной вычислительной системы из трех важнейших свойств – атомарности изменений, целостности данных и устойчивости к сбоям узлов – увы, одновременно выполняться могут только два.
В докладе очень не понравилось то, что авторы регулярно начинали спорить между собой о том, чье определение лучше, как правильнее расклассифицировать способы «партицирования» (как они это называют), и вообще, как будто между слов скатываясь к тому, кто из них более настоящий программист.
Это все продолжалось довольно долго, слушать перепалки было неприятно, большой пользы видно не было, и я ушел, немного не дождавшись окончания доклада.
- Сравнительный анализ хранилищ данных (Олег Царев и Кирилл Коринский на ADD-2010)
Думал, что будет интересно про «Sql vs NoSql». Начало было очень жиденькое. Целый час два человека с запинками и перебивая друг друга рассказывали, что Facebook ну никак физически не поместится на одном сервере БД. Очень странно. Всем, кто слушает Радио-Т, давно известно, что любой сайт может поместиться на одном сервере с Internet Information Server, надо его только правильно настроить (ну и MSSQL поставить).
Доклад был длинный, на вторую часть я не мог остаться, так как параллельно был доклад Андрея. Возможно, во второй части и было что-то содержательное.
Очень интересно негодовал в процессе доклада Андрей Аксенов, он даже в процессе написал на ноутбуке тест за 15 минут, чтобы опровергнуть на два порядка оценки докладчиков о производительности памяти.
- Сравнительный анализ хранилищ данных (Олег Царев и Кирилл Коринский на ADD-2010)
Выступали вдвоем, друг друга перебивали, спорили, порой казалось, что сейчас подерутся. Слайды были без картинок, без уточнения определений, и вообще слабо понятны сходу. (Кстати, подобными слайдами грешили и другие докладчики на этой конференции. Порой возникало ощущение, что люди просто не пожелали хорошо подготовиться.)
Стас Фомин 20:15, 5 октября 2010 (UTC): Мы неоднократно рассылкали и публиковали памятки-обращения к докладчикам. См. например, [1]. Просто мало из потенциальных докладчиков в курсе, «что такое хорошо». В основном только профессиональные евангелисты.Олег и Кирилл рассказывали об организации данных для соц-сетей на примере организации взаимодействия между участниками сети, рассматривали матрицу смежности и пытались подсчитать стоимость проекта, который эту задачу решит. Получалось, что при любом подходе нужно искать компромисс по трем осям:
- memory, CPU
- latency
- сложность кода
Возникают производные оси:
- бюджет проекта
- сроки
- лимит разработчиков
- аппаратура
- инструменты
Выводы:
- универсальных решений нет
- цель менеджера проекта — найти компромисс, локальный оптимум
- иногда задача неразрешима в заданных условиях
- обычно в итоге приходят к кластеру
Рассматривали партицирование данных:
- горизонтальное-вертикальное
- ручное
- автоматическое
Далее был рассказ про CAP-теорему, на середине которого я сбежал на другой доклад.
Любые правки этой статьи будут перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion».