Riak — простая, предсказуемая и масштабируемая БД. Преимущества и недостатки (Илья Богунов, ADD-2012)
Содержание
Аннотация
- Докладчик
- Илья Богунов
Как выглядит стандартный путь rdbms по мере ее роста? Примерно так:
- SQL-запросы с минимальным включением мозга — просто делающие то, что надо.
- Добавление индексов и лимитов в особо злостные места.
- Внешнее кэширование, асинхронные очереди, реплика, иногда самописные демоны на си/node.js/etc.
- SSD/RAID, десятки и сотни гигабайтов памяти, чтоб держать dirty page buffer побольше.
- Предагрегирование части (или всех) запросов типа GROUP BY/COUNT, так как делать их «на лету» по большой бд — слишком дорого.
- Функциональный шардинг, опционально partioning больших таблиц.
- Шардинг по ключу (юзеру/документу).
В итоге к концу пертурбаций имеем вроде бы реляционную базу, но фактически:
- Нет джойнов,
- Нет транзакций (так как их довольно сложно сделать меж шардами),
- Нет триггеров (опять же вся логика межкластерного взаимодействия в коде),
- К таблицам нельзя сделать сколько-нибудь сложный запрос (не дай бог сделать GROUP BY или SELECT не по индексу или с большим количеством random-seek`ов),
- Сложно изменять схему, добавлять индексы.
Ну и где PROFIT ? Стоило ли проходить весь этот путь?
Фактически по мере развития бд мы превратили ее в не-очень-то подходящее key-value с набором костылей, чтоб это все работало и не сильно тормозило, да и еще, скорее-всего, с единой точкой отказа в виде мастер-сервера. Может быть стойло попробовать пойти по другому пути? Который бы сразу вел нас по дороге высокой доступности, линейной масштабируемости и отсутствия единых точек отказа?Есть альтернативный путь — использование Riak как средства хранения данных, разработанного с фокусом на высокой доступности и устойчивости, а так же операционной простоте:
- Вместо того, чтобы писать хитрые схемы миграции данных и ребалансировки, вы просто делаете riak-admin join riak@node.
- Вместо того чтобы разбираться с распределенными транзакциями и миграциями данных вы просто работаете с key-value хранилищем (которое правда умеет учитывать конфликты записи).
Но это не волшебная таблетка:
- Если в RDBMS индекс и count(*) были всего лишь парой строк sql`я, то реализация того же самого в распределенной системе уже не такая простая задача.
- Атомарность операций — практически нонсенс в распределенной системе. Запись может потеряться, а потом «найтись», индекс может рассинхронизироваться с данными.
- И другие нюансы …
Цель этого доклада: рассказать о том, как это сделано в Riak`e, почему оно сделано так, пояснить, что это все не бесплатно и какую придется пройти learning curve. Ну и понять, какие задачи можно решать с его помощью, что можно, а что не желательно делать и какие подводные камни могут встретится на этой дороге.
Видео
Слайды




















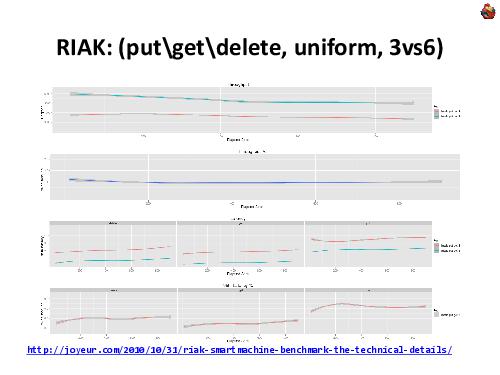
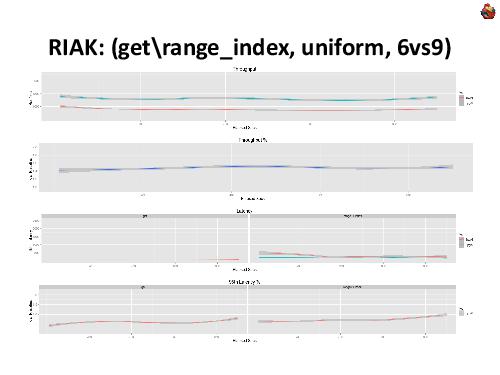
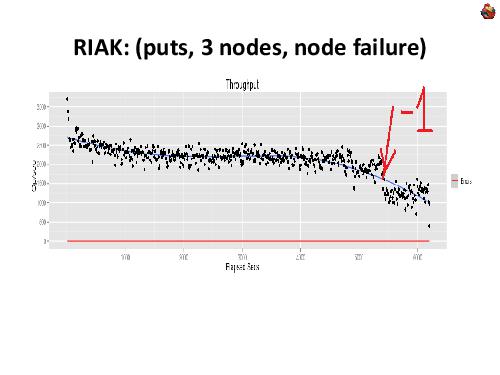
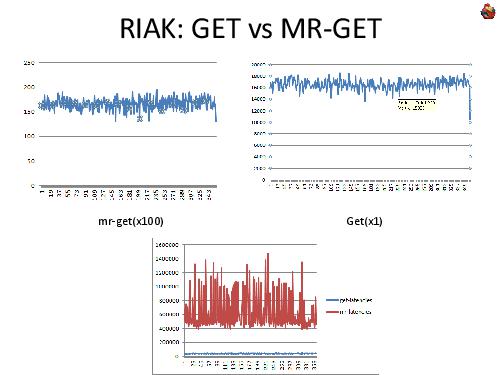












Примечания и отзывы
- Обсуждение у автора → http://techmnd.blogspot.com/2012/06/addconf-riak.html
- Страничка доклада на сайте конференции
Любые правки этой статьи будут перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion».